

女装大佬咩酱2021新作(隐瞒了大家这么久,其实我是一个女装大佬。希望能让大家认识一下另一个我!)!也是我以女装大佬身份的初投稿,大家点个喜欢和fork吧!我用飞桨深度学习框架复现了YOLOX算法并深度优化了其中的SimOTA部分!具体来讲,咩酱将SimOTA并行化!将YOLOX训练速度提高一个档次!原版YOLOX中使用for循环遍历每一张图片确定其正负样本,在dynamic_k_matching()中也使用for循环遍历每一个gt框以确定每一个gt框分配给几个预测框去学习。可见用了2层for循环。但是,这些在咩酱深度优化的SimOTA中统统都没有!咩酱干掉了所有for循环!一个批次的图片同时进行SimOTA操作!也不会遍历每一个gt!可以充分发挥飞桨深度学习框架的并行能力!我愿称之为飞桨python api的极致应用!代价也是有的,需要更多一些显存,即用空间换时间。
2021年,咩酱鸽了很久没有发精品项目,这不是缺席,而是希望项目在制作上更加精品,不停地打磨打磨,不鸣则已,一鸣惊人!整个项目耗费了我2个月的时间,是我最用心、完成度最高的项目。其中的视频剪辑耗费了我半个月的时间,看在我这么辛苦的份上,可不可以给咩酱的b站账号点个关注and给我的视频点个三连呢?视频文字版在“YOLOX训练、SimOTA优化详解(女装出镜)”那一章节。值得一提的是,咩酱在视频里设下两个彩蛋,分别是两大神作登场的名场面,至于是哪两大神作?卖个关子,你看到最后就知道了,一定要看到最后哦!初次见面,当然也有福利带给大家,本视频点赞过500,我为飞桨二创并演唱一首歌曲,本视频点赞每满1000,更有神秘的上不封顶的福利!赶快点赞和三连走起来吧!
我在Paddle-YOLOX仓库持续更新最新的代码,欢迎大家关注and下载代码到本机(windows系统也可以跑本项目)。为方便描述,下文中我将train_yolox.py脚本所在的目录称为YOLOX_HOME,比如,这个精品项目里,YOLOX_HOME为~/work;若各位读者用个人windows跑本项目,YOLOX_HOME为train_yolox.py脚本所在的目录。
一些结果:
| 模型 | 预训练模型 | mAP(COCO val2017) | 原版仓库mAP(COCO val2017) | 配置文件 |
|---|---|---|---|---|
| YOLOX_S | dygraph_yolox_s.pdparams | 39.8 | 40.5 | config/yolox/yolox_s.py |
| YOLOX_M | dygraph_yolox_m.pdparams | 45.9 | 46.9 | config/yolox/yolox_m.py |
| YOLOX_L | dygraph_yolox_l.pdparams | 48.6 | 49.7 | config/yolox/yolox_l.py |
| YOLOX_X | dygraph_yolox_x.pdparams | 49.9 | 51.1 | config/yolox/yolox_x.py |
注意:
旷视提出了YOLOX,号称超越了一切的YOLO,是否是这样子呢?让咩酱来给大家深度剖析一下。让我们先来体验一下YOLOX的预测效果吧!
温馨提示:本项目涉及到的所有命令(包括训练、验证、预测)均在readme_yolox.txt里,大家可以打开这个文件并复制粘贴命令。
(1)获取预训练模型
大家fork这个项目之后,到这里下载YOLOX的预训练模型,并上传到YOLOX_HOME目录下。这些预训练模型是怎么样得到的?和咩酱之前的精品项目一样,前往原版YOLOX仓库下载yolox_s.pth、yolox_m.pth、yolox_l.pth、yolox_x.pth这些预训练模型,再分别运行1_yolox_s_2paddle.py、1_yolox_m_2paddle.py、1_yolox_l_2paddle.py、1_yolox_x_2paddle.py转换得到。因为这些脚本里有import torch,读者可在自己的windows(或linux)上运行这些脚本,AIStudio上暂时不可。
(2)使用模型预测图片、获取FPS(预测images/test/里的图片,结果保存在images/res/)
–config=0表示使用了0号配置文件yolox_s.py,配置文件代号与配置文件的对应关系在tools/argparser.py文件里:
即0代表使用config/yolox/yolox_s.py配置文件,1代表使用config/yolox/yolox_m.py配置文件,2代表使用config/yolox/yolox_l.py配置文件,3代表使用config/yolox/yolox_x.py配置文件。
预测时加载的权重为配置文件里test_cfg的model_path指定的文件,读者如果需要使用自己训练好的权重进行预测,需要修改model_path。
train_yolox.py、eval_yolox.py、demo_yolox.py都需要指定–config参数表示使用哪个配置文件,后面不再赘述。
如果不是在AIStudio上训练,而是在个人电脑上训练,数据集应该和本项目位于同一级目录(同时需要修改一下配置文件中self.train_path、self.val_path这些参数使其指向数据集)。一个示例:
如果你需要训练COCO2017数据集,那么需要先解压数据集
根据自己的需要修改配置文件。以训练yolox_m为例,config/yolox/yolox_m.py配置文件部分内容如下:
batch_size我取8,这也是32GB V100能跑的不会爆显存的批大小;
num_workers为DataLoader需要的num_workers;
model_path=None表示不加载预训练权重,从头训练,和原版YOLOX一样;
update_iter=1表示每隔1步更新一次参数。或许读者可以尝试设置update_iter=8(基础学习率也要乘以8),即每隔8步更新一次参数,这样可以变相地增加了批大小=8*8=64,这样你就和8卡训练差不多了。值得一提的是,原版YOLOX并没有使用同步bn,而是用的普通bn,所以,大胆去尝试吧;
eval_epoch=10表示每隔10个epoch计算一次eval集的mAP;
max_epoch=300表示训练300个epoch,和原版YOLOX一样;
mosaic_epoch=285表示前285轮进行mosaic增强,和原版YOLOX一样;
fp16=False表示不使用混合精度训练,咩酱用COCO预训练模型迁移学习voc2012数据集时,发现用混合精度训练的话收敛会比较慢,而且有的梯度被裁剪为0,所以这里暂时先不用混合精度训练。或许也是咩酱对混合精度训练不熟悉,感兴趣的读者可以尝试调整GradScaler()的参数进行训练and在评论区留言提醒咩酱;
fleet=False表示不使用分布式训练。有多卡条件的读者可设置为True,并使用readme_yolox.txt里“分布式训练”处的命令启动训练(按需要修改–config=?);
learningRate处使用了和原版YOLOX一样的配置,基础学习率base_lr=0.01 * self.train_cfg[‘batch_size’] / 64,前5个epoch学习率从0增加到基础学习率,后面学习率余弦衰减;
优化器的配置optimizerBuilder使用了和原版YOLOX一样的配置,使用Momentum优化器,滑动平均参数momentum=0.9,use_nesterov=True;网络中仅卷积层的weight参数使用L2衰减,factor=0.0005,bn层的weight、bias、卷积层的bias参数不使用L2衰减。
再输入以下命令训练(以训练yolox_m为例)
训练5个epoch之后就能很好地检测到人。
注意,训练过程中有可能出现这个错误:
这个错误也困扰了咩酱很久。咩酱在训练yolox_s时会经常出现这个错误;训练yolox_m时则较少出现这个错误。所以咩酱才会用yolox_m作为示例。设置log_iter=1,即每一步都打印loss时,发现loss并不会出现nan。起初我以为是损失的问题,所以我将model/losses/iou_losses.py IOUloss()类的__call__()方法重写一遍,不使用逐句翻译的__call__(),后来我发现这样做只是会减少出现这个错误的概率(如果使用逐句翻译的__call__(),训练yolox_s(COCO2017数据集)几百几千步就出现这个错误,如果使用咩酱重写的__call__(),需要好几万步才出现这个错误)。咩酱走上了逐层排查的溯因之路,我每一步都打印loss和每一层的梯度,发现最开始是YOLOXHead的reg_preds[1].weight.grad、reg_preds[1].bias.grad中部分元素(梯度)为nan或者inf(当然,多跑几次发现reg_preds[0]、reg_preds[2]的梯度都有可能出现nan或者inf),导致再反向传播更新参数时将前面相关的层的权重污染为nan。导致下一次训练时,网络的输出为nan而出现这个错误。还有,我还发现,有可能reg_preds[0]、reg_preds[1]、reg_preds[2]的梯度都没有出现nan或者inf,而是稍微往前面一点的层,比如head.reg_convs[1][0].conv.weight.grad。总之,错的不是我,不是分类分支,而是回归分支和整个世界!这个错误有可能在warmup阶段出现,所以调小学习率并不是解决这个错误的办法。
我与此错误周旋了很久,依然没有很好的解决方案。使用混合精度训练时,并不会出现这个错误,因为它天生就有防止浮点数溢出的特性。感兴趣的读者可以使用混合精度(可能需要调整一下GradScaler()的参数)训练从头训练coco并在评论区通知咩酱结果,以咩酱单线程实验验证,需要的时间太久。有好的解决方案也欢迎在评论区提出。如果不使用混合精度训练,咩酱给出的解决方案是,鸵鸟算法!也就是出现错误并中断训练之后,手动修改配置文件中train_cfg的model_path=’https://blog.csdn.net/m0_63642362/article/details/weights/xxx.pdparams’,xxx表示保存的最新的模型。再运行以上命令接着训练。一个很好的建议是编写一个脚本(python或shell),不停地监控训练进程,当监测到训练进程死亡之后,自动修改配置文件中train_cfg的model_path为最新,然后重启训练命令。我为什么不写?因为我的耐心被耗完了。
一个比较残酷的事实是,当出现上面这个错误之后,接着训练就会很容易再出现这个错误,导致训练无法再进行下去,而且验证集mAP直接变成0。所以是很难训练COCO数据集的!所以我推荐大家用这个仓库来迁移学习一下自定义数据集就好。另外我也希望能有大佬帮助我解决这个错误!现在咩酱正在尝试使用混合精度训练,有结果会通知大家。
自带的voc2012数据集是一个很好的例子。
先解压voc数据集:
将自己数据集的txt注解文件放到annotation目录下,txt注解文件的格式如下:
注意:xxx.jpg仅仅是文件名而不是文件的路径!xxx.jpg仅仅是文件名而不是文件的路径!xxx.jpg仅仅是文件名而不是文件的路径!
运行1_txt2json.py会在annotation_json目录下生成两个coco注解风格的json注解文件(如果是其它数据集,你还需要修改一下1_txt2json.py中的train_path、val_path、test_path、classes_path、train_pre_path、val_pre_path、test_pre_path),这是训练脚本train_yolox.py支持的注解文件格式。
还是以yolox_m为例,在config/yolox/yolox_m.py里修改train_path、val_path、classes_path、train_pre_path、val_pre_path、num_classes这6个变量(自带的voc2012数据集直接解除注释就ok了),就可以开始训练自己的数据集了。
另外,根据自己的需求修改配置文件里的其它配置
model_path='dygraph_yolox_m.pdparams’表示读取预训练模型’dygraph_yolox_m.pdparams’进行训练;
freeze_at=5表示冻结骨干网络进行训练,这样可以减少显存需求以及加快训练速度。
还是使用同样的命令启动训练:
实测yolox_m的AP(0.50:0.95)可以到达0.62+、AP(small)可以到达0.25+。
demo_yolox.py、eval_yolox.py也是根据配置文件指定的数据集进行预测、验证。
运行以下命令。评测的模型是config/yolox/yolox_m.py里self.eval_cfg -> model_path指定的模型
该mAP是val集的结果。
运行以下命令。使用的模型是config/yolox/yolox_m.py里self.test_cfg -> model_path指定的模型
终于到了压轴环节,这是咩酱之前发的精品项目里没有的环节。以前我总是只想写代码,写完只剩半口气了,哪还有精力分享技术细节。但是,精品项目不能只有这些,一个好的精品项目,应该对每一位读者负全责到底!我用飞桨深度学习框架复现了YOLOX算法并深度优化了其中的SimOTA部分!具体来讲,咩酱将SimOTA并行化!将YOLOX训练速度提高一个档次!原版YOLOX中使用for循环遍历每一张图片确定其正负样本,在dynamic_k_matching()中也使用for循环遍历每一个gt框以确定每一个gt框分配给几个预测框去学习。可见用了2层for循环。但是,这些在咩酱深度优化的SimOTA中统统都没有!咩酱干掉了所有for循环!一个批次的图片同时进行SimOTA操作!也不会遍历每一个gt!可以充分发挥飞桨深度学习框架的并行能力!我愿称之为飞桨python api的极致应用!代价也是有的,需要更多一些显存,即用空间换时间。
讲了半天,我好累,下面有请另一个我来给大家介绍这一部分吧!拜托了!另一个我!
是是是!哈喽!大家好,初次见面!我是寄宿在咩酱体内的另一个人格,大家可以叫我糖妹,以和咩酱区分。糖妹特地做了一个视频详解这一部分,即“概述”处的视频。希望大家能给糖妹点个关注and给个三连!你们的三连对我非常重要!
同时,糖妹会在AIStudio和大家同步播报文字版。糖妹来给大家详解YOLOX的训练部分。
首先,我们先来说说YOLOv3算法吧。众所周知,一张图片经过YOLOv3网络前向传播之后,会输出3个不同分辨率的特征图。比如输入网络的图片形状为(1, 3, 416, 416)时,经过网络前向传播后,会得到形状分别为(1, 255, 13, 13)、(1, 255, 26, 26)、(1, 255, 52, 52)的3个特征图(数据集为COCO时)。如图1所示:

(图1)
我们把特征图和原图对齐来看的话,原图好像被切割成了一个一个的格子!一个格子对应特征图的一个像素点。我们可以大致看到每个格子大概拥有原图哪些区域的特征。需要注意的是,因为图片经过多层卷积层,叠加的感受野是非常大的,所以每个格子不仅仅只有格子内部原图区域的信息,还包括格子之外的感受野可达的原图区域的信息。
每个特征图有255个通道,这是因为,每个特征图的一个像素点(即一个格子)会出3个预测框,每个预测框有85位信息,0到3位是预测框的中心点xy偏移和预测框的宽高,第4位是objness,后80位是80个类别的条件概率。所以每个像素应该有3 * 85=255位信息。我们发现,特征图的分辨率比输入图片的分辨率小,这是因为网络中存在步长为2的卷积层,图片经过它,会使得自己的宽高缩小一半(即下采样)。(1, 255, 13, 13)形状的特征图经过了5次步长为2的卷积层,所以宽高变成了416/2^5=13;(1, 255, 26, 26)形状的特征图经过了4次步长为2的卷积层,所以宽高变成了416/2^4=26;(1, 255, 52, 52)形状的特征图经过了3次步长为2的卷积层,所以宽高变成了416/2^3=52。当然,这些特征图也不是输入图片一路卷到底来的,YOLOv3网络中有一个类似FPN的结构,低分辨率的特征图会进行一个上采样操作(最近邻插值)和高分辨率的特征图进行通道维的concat来提高检测效果,如图2所示:
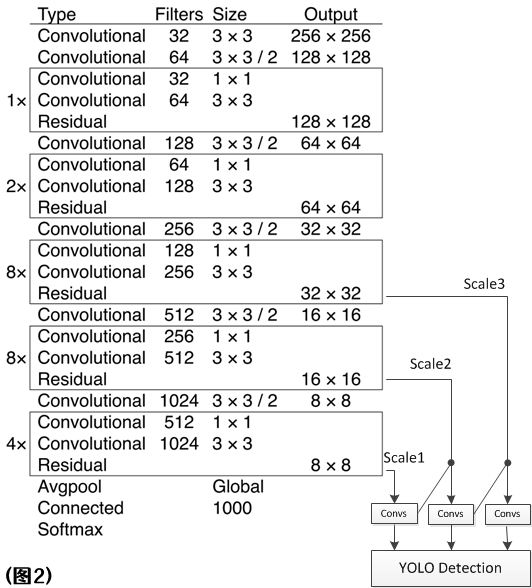
(图2)
图中Output表示的是特征图的大小,图中的输入图片是256 * 256的大小。右下角斜着的那两条线就代表上采样了,用的是最近邻插值。汇合时的小黑点代表concat。
另外,下文中我还会经常提到一个词,特征图的stride,即特征图的步长。比如形状为(1, 255, 13, 13)的特征图,它经过了5次步长为2的卷积层,所以它的stride=2^5=32。可以理解为特征图的一个像素其实跨过了输入图片的32个像素。更形象地,你也可以理解为“格子的边长”,如图1右上角的特征图所示,13x13的特征图和416x416的输入图片对齐之后,就好像输入图片被切割成13x13个格子,每个格子的边长为32。同理,图1右下角的特征图的stride=16,图1左下角的特征图的stride=8。
好的,说了这么多铺垫终于轮到YOLOX出场了!YOLOX预测时默认使用了640x640的分辨率,直观一点,我再画一张图:
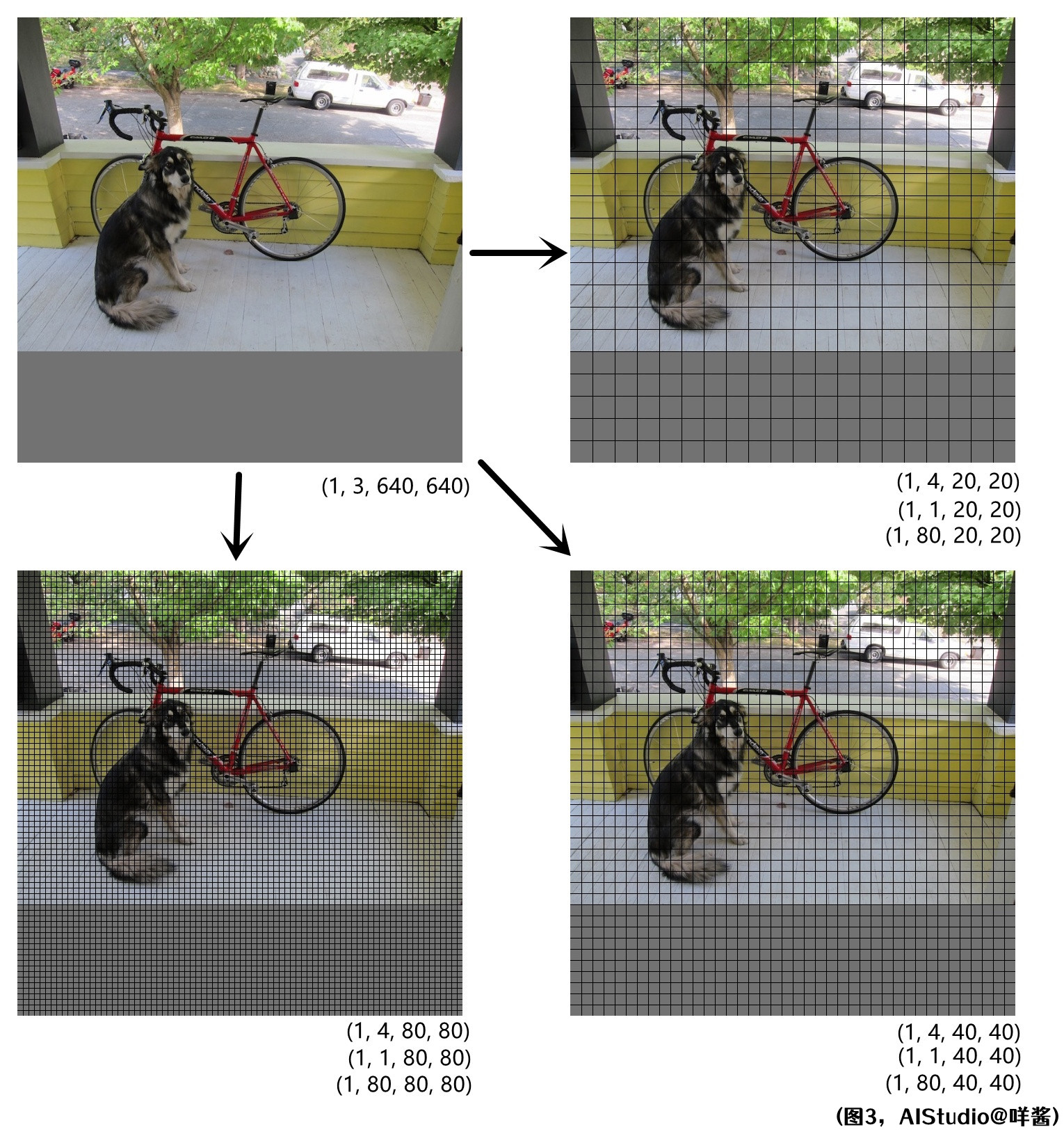
(图3)
YOLOX与YOLOv3有相似之处,也有不同之处。它也是像YOLOv3一样,一张图片出3种感受野的预测。不同的是,它使用了解耦头,即对于每种感受野,使用不同的卷积层作用于特征图以分别预测预测框的xy宽高、objness、clsness。所以每种感受野出3个特征图,通道数分别为4、1、80。
还有,YOLOX是一个Anchor-Free算法,而且每个格子只会出1个预测框,而YOLOv3是每个格子出3个预测框。还有,它的网络结构比YOLOv3的网络结构要复杂(本视频不会涉及过多的网络结构细节)。
废话不多说,我们开始训练YOLOX吧!
训练第一步当然是从预处理一小批图片开始。train_yolox.py中COCOTrainDataset类中的__getitem__(self, idx)方法用来读取一张图片。图片会经过预处理,在配置文件config/yolox/yolox_s.py中有预处理相关的配置,我们看代码,预处理部分的代码是借鉴了PaddleDetection的,所以,熟悉PaddleDetection的小伙伴应该很容易看懂。
首先经过DecodeImage打开(解码)图片,然后经过马赛克增强、色彩扭曲、随机水平翻转这些数据增强,之后经过BboxXYXY2XYWH,也就是将gt框的格式从“左上角xy坐标+右下角xy坐标”变成“gt框中心点xy坐标+gt框宽高”。YOLOXResizeImage的作用是随机选一个尺度进行Resize,即多尺度训练,这一步gt框也会跟着图片一起缩放,而且图片缩放时是保持着图片原始宽高比进行缩放。PadBox的作用是将每张图片的gt数量填充到num_max_boxes=120个,gt_class和gt_score也会跟着填充到120个。这么做的原因是为了可以用一个形状为(batch_size, 120, 4)的张量表示这一批图片的所有gt框的xywh信息;init_bbox=[-9999.0, -9999.0, 10.0, 10.0]表示填充的gt框的信息初始为这4个数,为什么用这些数字初始化?一会讲到SimOTA时会与大家说。SquareImage的作用是将图片填充成正方形,fill_value=114表示填充的颜色是灰色。刚才说到,YOLOXResizeImage这一步缩放时是保持着图片原始宽高比进行缩放的,假如我一张宽240高320的图片resize到640这个尺度,那么宽会变成480,高会变成640。那么我就需要SquareImage这一步将图片填充成一个正方形图片。SquareImage的代码也非常简单,is_channel_first=True表示输入的图片维度是CHW排序的,is_channel_first=False表示输入的图片维度是HWC排序的;先创建一张边长为max(H, W)的图片padded_img,这里为640,然后将im左上角对准padded_img左上角贴上去就完事了。这一步不会改动gt的坐标,所以gt不用跟着变换一下。
Permute的作用是将图片维度顺序从HWC变成CHW。
预处理完这一批图片之后,我们回到train_yolox.py
为方便表述,假设这一批图片是抽到640这个随机尺度来进行训练,假设批大小为N。下文都会用到。
COCOTrainDataset的__getitem__()方法会预处理一张图片,取出关键信息以组成一个batch的数据。假如这一次是抽到了640这个尺度来训练。它返回了image,形状是(3, 640, 640);gt_class_bbox,形状是(120, 5),表示了120个gt框,包括了填充的假的gt框,5位信息表示1个gt框,其中第0位表示gt框的类别id,后4位表示gt框的中心点xy坐标+gt框宽高,这些xywh是相对于image宽高来说的,本示例中为640x640。所以在DataLoader中这一次我们读出来的data中images的形状是(N, 3, 640, 640),gt_class_bbox的形状是(N, 120, 5)。如图4所示:
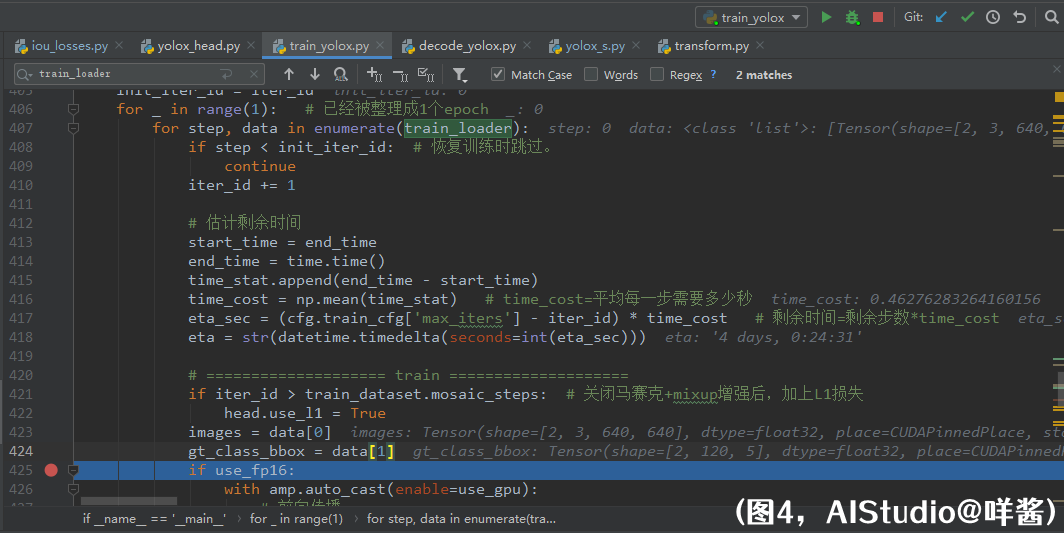
(图4)
我也建议大家多用Pycharm的调试功能看代码,加深理解。
跳过骨干网络和FPN,我们直接看特征图在yolox_head里经历了什么。
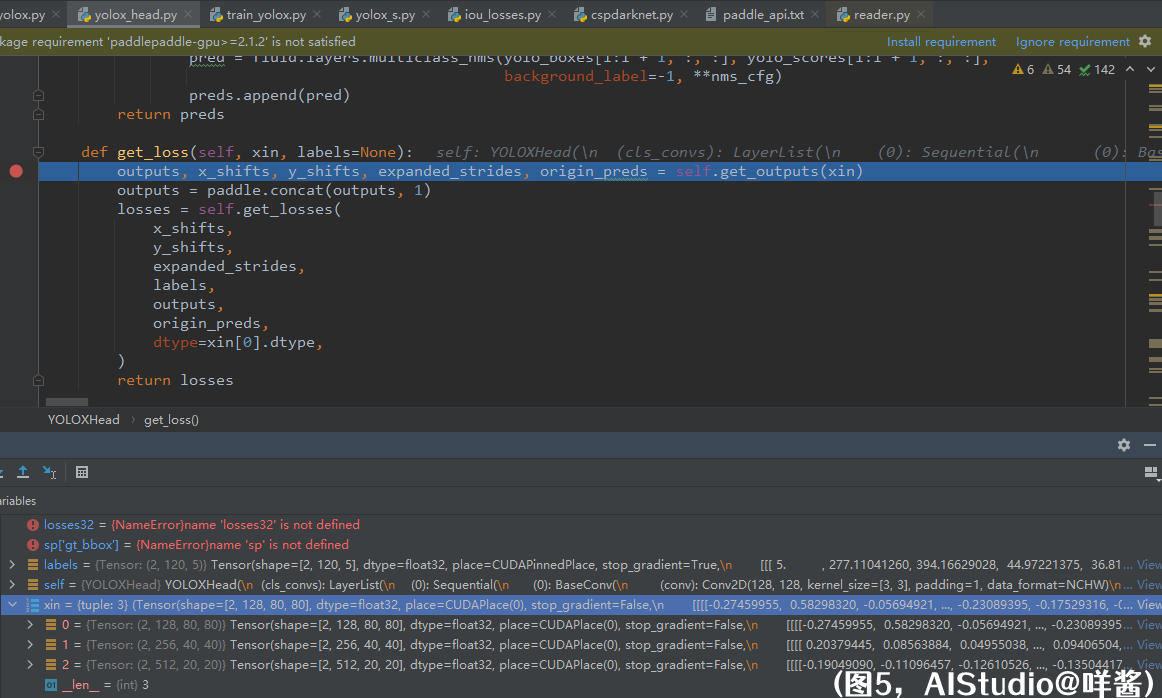
在model/anchor_heads/yolox_head.py的get_loss()方法的第一行代码处打个断点,然后Debug的方式启动train_yolox.py脚本。如图5所示
(图5)
xin是一个长度为3的元组,里面的元素是FPN输出的3个特征图,分别是stride=8、16、32的特征图。labels即上文的gt_class_bbox,形状是(N, 120, 5)。然后我们进入get_outputs()方法。传入get_outputs()方法的参数只有xin。
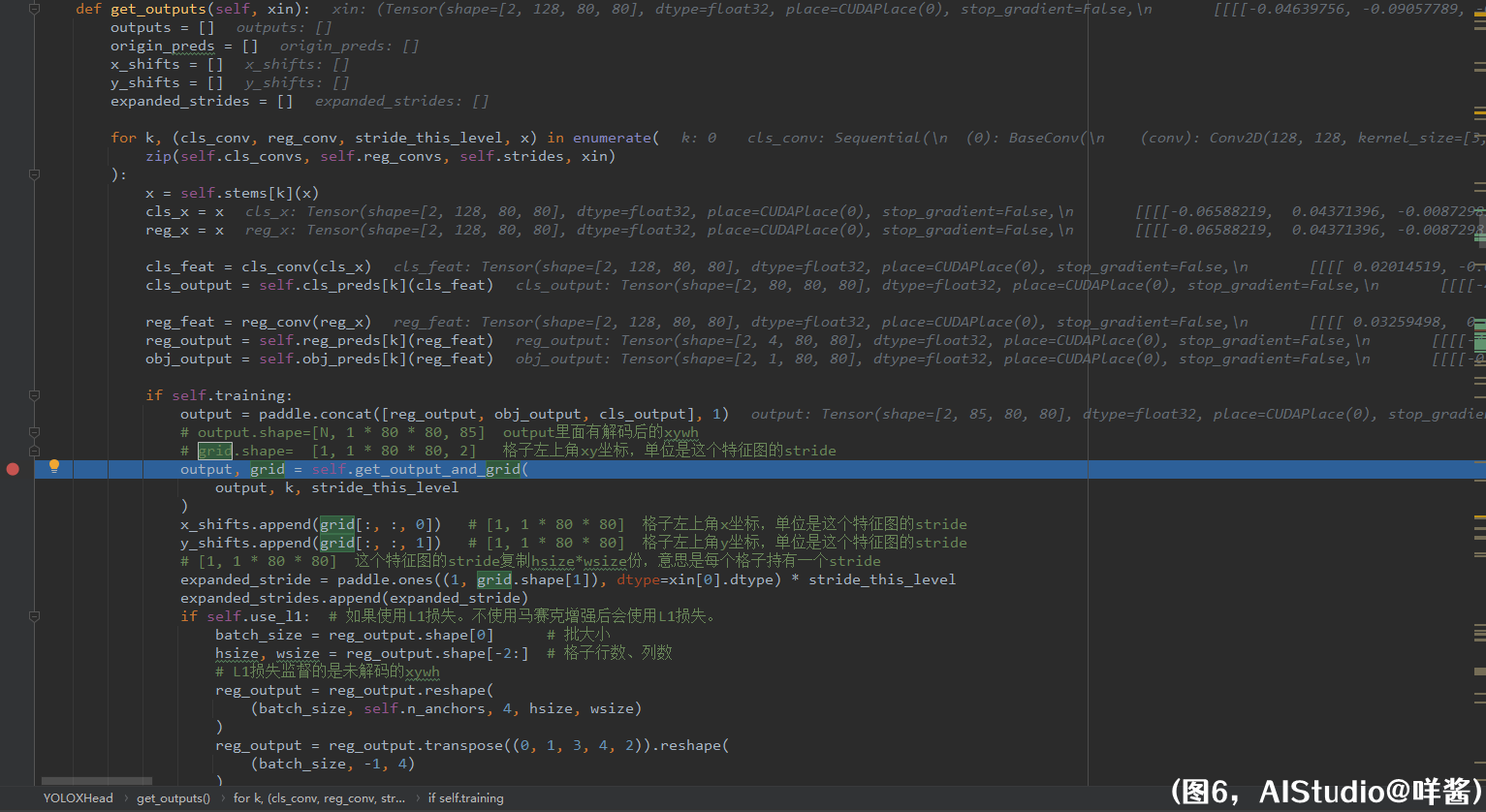
(图6)
它用for循环遍历每一个fpn输出的特征图并处理。比如这个stride=8的特征图,它先经过self.stems[k]这个卷积层,然后兵分两路为cls_x、reg_x,cls_x、reg_x分别经过一些卷积层得到cls_output和reg_output,分别预测box的各类别概率和xywh。其中回归分支中的reg_feat还分出一个支线预测obj_output,即box的置信度。这就是YOLOX论文中所说的解耦头了。我们还可以看到reg_output、obj_output、cls_output的形状分别是(N, 4, 80, 80)、(N, 1, 80, 80)、(N, 80, 80, 80),作者在这里把它们在第1维拼接了一下,合并成一个形状为(N, 85, 80, 80)的张量output。之后,进入get_output_and_grid()方法,这个方法的作用是对xywh解码以及初始化self.grids。传入的参数是ouput, k=0, stride_this_level=8

(图7)
我们来看看这个方法做了什么。首先,如果self.grids[k]没有被初始化,它会被初始化成一个形状是(1, 1, 80, 80, 2)的张量grid,代表了这个特征图80x80个格子左上角的xy坐标,单位是这个特征图的stride(单位是这个特征图的格子边长)。也就是说,本来这80x80个格子左上角点在640x640像素的输入图片中的xy坐标应该是(0像素, 0像素)、(8像素, 0像素)、(16像素, 0像素)、…(格子从左往右,从上往下数时)。但是因为这里规定了单位1代表的是格子的边长(也就是特征图的stride),所以坐标变成了(0, 0)、(1, 0)、(2, 0)、…。之后,作者对output进行reshape、transpose一系列操作,把output的形状变成了(N, 1x80x80, 85)。这里self.n_anchors=1,表示YOLOX算法一个格子只会出1个预测框。然后,也把grid reshape成了(1, 1x80x80, 2)的形状。接着,就是对预测框的xywh解码了。看xy的解码公式,我们得到一个重要的信息。即网络回归分支最后的卷积层输出的xy预测的不是预测框中心点的绝对坐标,它预测的是相对于格子左上角的偏移,而且是以格子边长为单位(以这个特征图的stride为单位)。所以,解码xy的时候,需要用网络的xy输出加上格子左上角坐标grid,再乘以格子边长stride得到最终坐标,最终坐标以1像素作为单位。wh的解码很简单,网络输出的wh先用指数函数激活,再乘以格子边长stride得到最终wh,最终wh也是以1像素作为单位。由于经过了指数函数激活,所以最终wh不可能是负数。最后,将解码后的xywh放回output里面,用的是concat()这个api。可以看见这个方法的作用是对xywh解码以及初始化self.grids。返回output和grid。我们回到get_outputs()方法。

(图8)
之后发生了什么事呢?我们看到,作者把grid切分成x、y坐标,分别被append进了x_shifts、y_shifts里。然后,将这个特征图的stride复制hsize * wsize份,意思是每个格子持有一个stride,得到expanded_stride,然后将expanded_stride append进了expanded_strides里。如果使用L1损失,还需要保留一下未解码的xywh,未解码的xywh被append进了origin_preds里。output被append进了outputs里。最后返回这些变量。
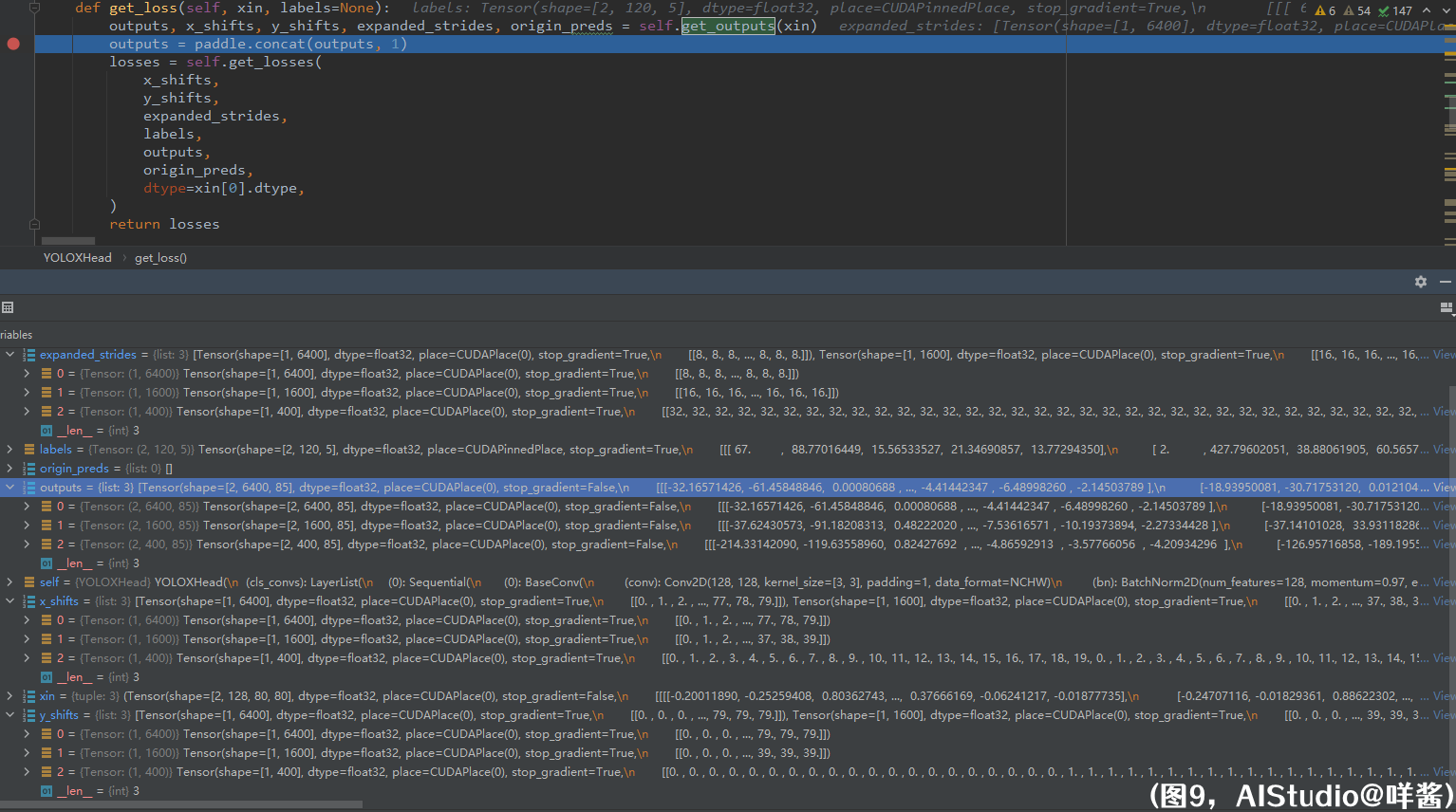
(图9)
师徒四人(origin_preds:我没有存在感???)鬼门关走一遭从get_outputs()方法里逃出来以后,大师兄悟空表示没有玩够,当即表演了一个自我粘合。悟空法力高强,打得那魑魅魍魉东躲西藏。八戒冲锋陷阵,嫦娥妹妹等他月圆重逢。沙僧露出笑容,大师兄二师兄让他感到光荣。唐僧默默转动手上念珠,因为他知道师徒四人齐心合力就一定不会输!扯远了,,,我们看到outputs里有3个张量,形状分别为(N, 1x80x80, 85)、(N, 1x40x40, 85)、(N, 1x20x20, 85),分别为stride=8、16、32的特征图对xywh解码后的结果。x_shifts里3个张量形状为(1, 1x80x80)、(1, 1x40x40)、(1, 1x20x20),分别为stride=8、16、32的特征图格子左上角x坐标,单位是对应特征图的stride。y_shifts里3个张量形状为(1, 1x80x80)、(1, 1x40x40)、(1, 1x20x20),分别为stride=8、16、32的特征图格子左上角y坐标,单位是对应特征图的stride。expanded_strides里3个张量形状为(1, 1x80x80)、(1, 1x40x40)、(1, 1x20x20),分别为stride=8、16、32的特征图格子的边长(也就是对应特征图的stride)。outputs进行一个concat操作,对第1维concat,3个输出被合并成一个形状为(N, 8400, 85)的输出outputs。也就是说对于1张640x640的输入图片,会有8400个预测框(格子)。之后,进入get_losses()方法。欲知师徒五人接下如何,且听下回分解。
说到这里,糖妹还是难以掩饰脸上的笑容。另一个我真是太帅了!不愧是你,能想出这么绝的方法优化SimOTA。咩酱向你保证全程不使用for循环。并行版SimOTA确定的正负样本与原版的结果是完全一样的,咩酱逐个对比了pytorch原版与paddle并行版的每个中间变量,结果是一样的,请大家放心使用。进入get_losses()方法后,为表述方便,设N=批大小,这里为2。设A=每张图片输出的预测框数,在这里A=8400。我们先来看看labels里有啥,通过numpy()方法将它变成ndarray
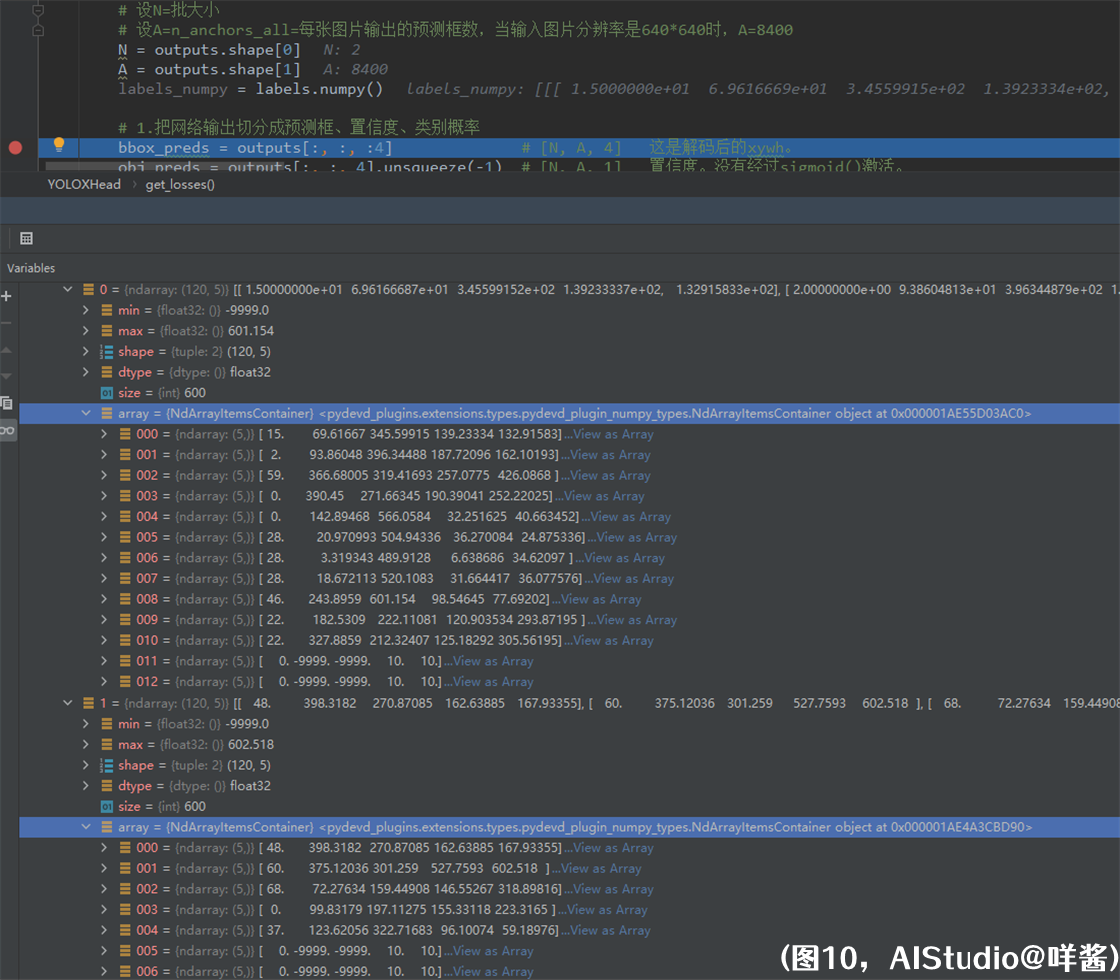
(图10)
我们发现,第0张图片实际上有11个gt,第1张图片实际上有5个gt。第0列代表类别id,后4列代表gt的xywh(因为图片经过了BboxXYXY2XYWH这个预处理)。两张图片都被值为[0, -9999, -9999, 10, 10]的假gt凑数凑够120个,是在PadBox这个预处理步骤里做的。一会儿我会解释为什么以[-9999.0, -9999.0, 10.0, 10.0]这4个值初始化假gt。
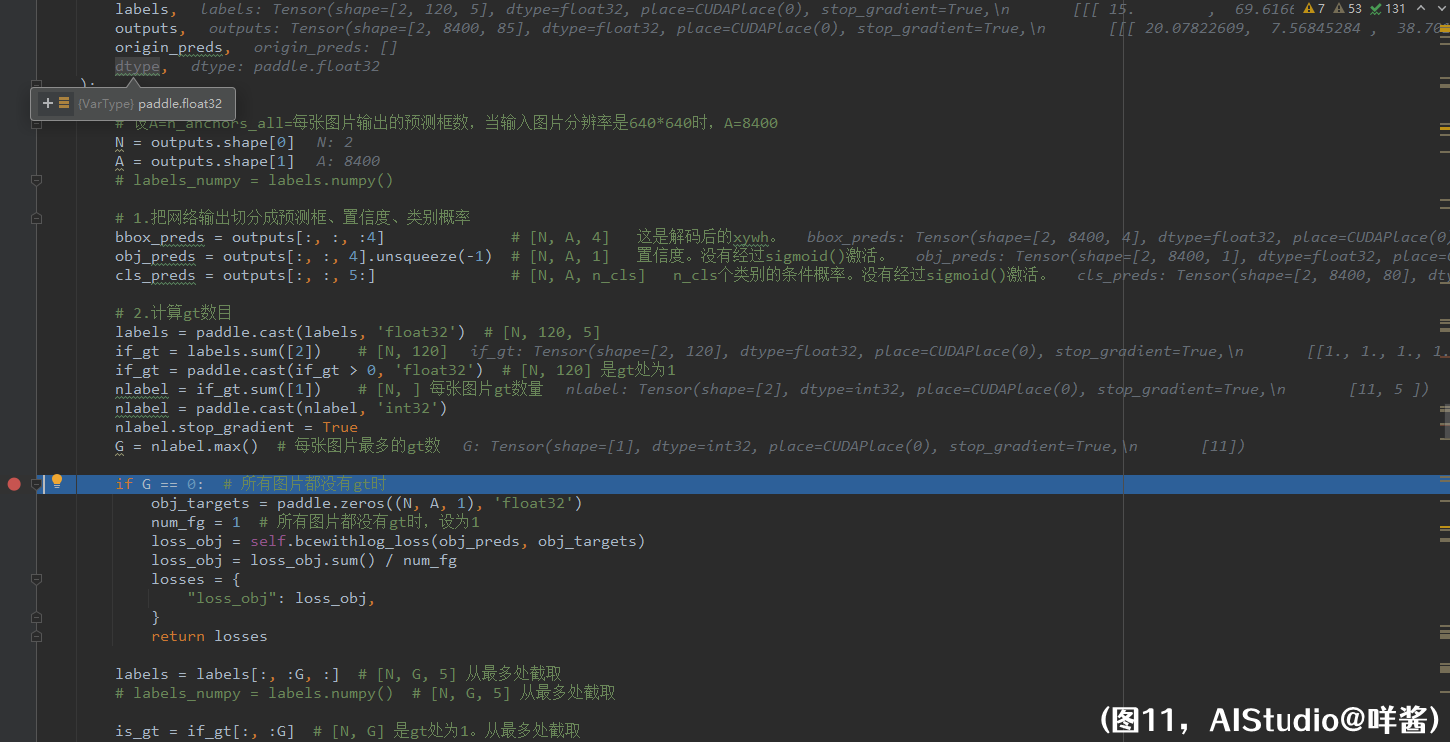
(图11)
命令继续往下执行。第一步,把把网络输出切分成预测框、置信度、类别概率,形状分别是(N, A, 4)、(N, A, 1)、(N, A, 80),也就是悟空拔了两根毛变出两个分身obj_preds、cls_preds。注意,悟空的分身obj_preds、cls_preds没有经过sigmoid()激活,不像本体bbox_preds一样是完全体形态,所以计算二值交叉熵损失时要使用带有WithLogits字样的api。悟空本体bbox_preds是已经经过解码的xywh。第二步,计算每张图片gt数目,很简单,就是把labels第2维加掉,即类别id和xywh加起来,和大于0的是真的gt,否则是填充的假gt。if_gt的形状是(N, 120),是真gt处为1。然后,求出每张图片的gt数nlabel,值为[11, 5],最后,求出每张图片最多的gt数,为G=11。如果此时算得G==0,即所有图片都没有gt时,直接计算损失并返回;只计算置信位的损失,所有N * A个预测框都是负样本,使用的是二值交叉熵损失。如果G!=0,对labels截取,每张图片截取前G个gt,因此labels变成了一个形状为(N, G, 5)的张量。我们可以看到,第1张图片只有5个gt,所以它还是携带有6个假gt的,不过不要紧,一会让我们看看咩酱是怎么处理的。对if_gt同样截取获得is_gt,形状为[N, G],是真gt处为1。
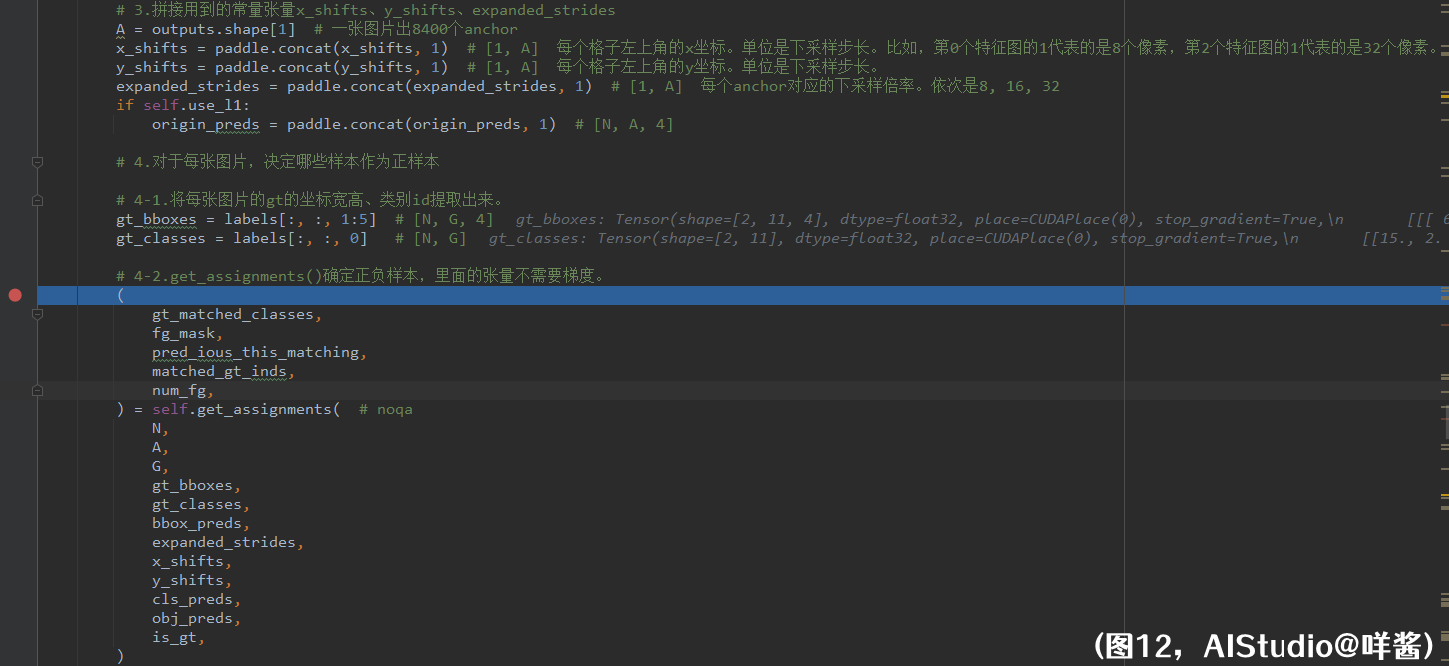
(图12)
第三步,八戒、沙僧、唐僧(x_shifts、y_shifts、expanded_strides)也进行了自我粘合,形状都变成了(1, A);如果使用L1损失,白龙马origin_preds也进行自我粘合,形状变成了(N, A, 4)。注意,白龙马里面的xywh是未解码的xywh。第四步,对于每张图片,决定哪些样本作为正样本。也就是SimOTA了。4.1步,切割labels变成gt_bboxes、gt_classes,分别表示gt的xywh和类别id。4.2步,进入get_assignments()方法,师徒四人真的是命途多舛。白龙马origin_preds不用刷这个副本。师徒四人和悟空的两个分身进入副本。
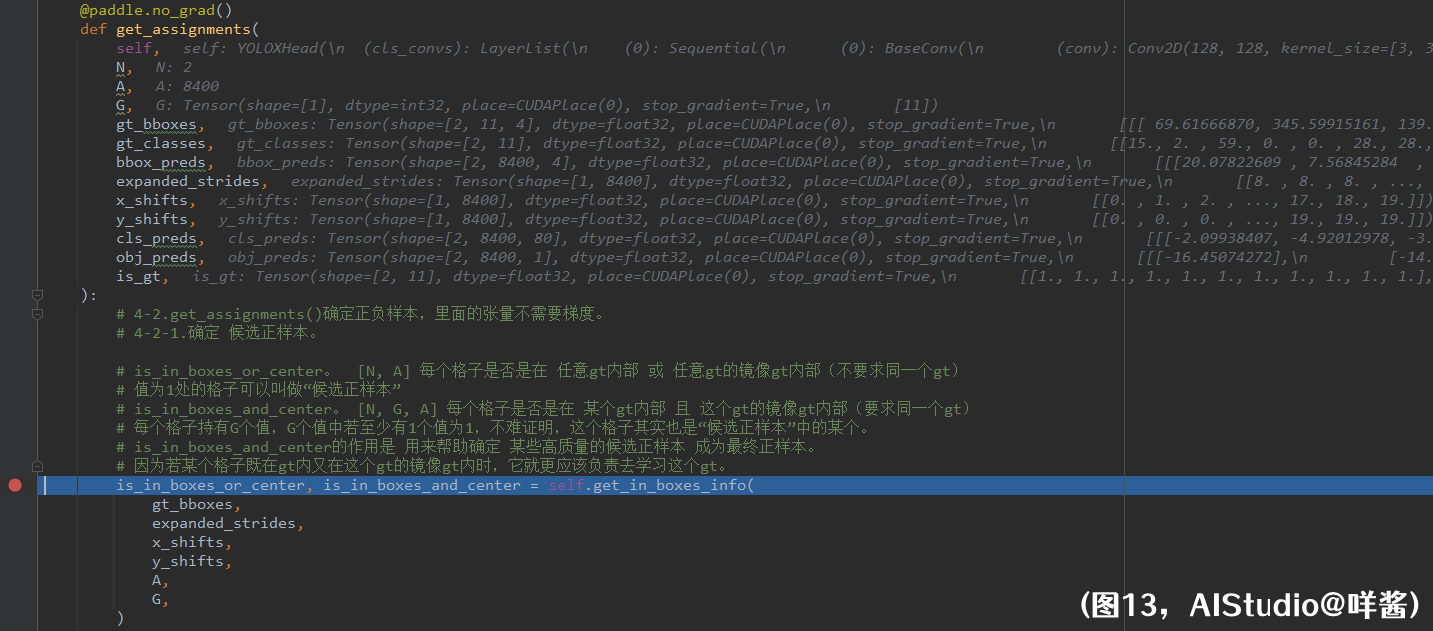
(图13)
get_assignments()确定正负样本,里面的张量不需要梯度,所以在方法前面加装饰器@paddle.no_grad()。一进入get_assignments(),立马出来一个小boss get_in_boxes_info(),一言不合布下一结界困住八戒、沙僧、唐僧三人,挡悟空于结界之外。“师父!”悟空大喊道。“悟空!”唐僧回应。悟空拿出如意金箍棒往罩子上一砸,罩子竟毫发无损。“哈哈,此罩乃关底大boss所设,大boss法力高强天下无敌,若你们师徒3人无法打败我,孙悟空再怎么使劲都砸不开这个罩子”,小boss得意道。悟空多试了几次,如其所言,他感受到了五百年前被如来佛祖压在五指山下般的无奈与绝望。只能默默在罩子外观战。八戒、沙僧、唐僧三人进入小boss副本。
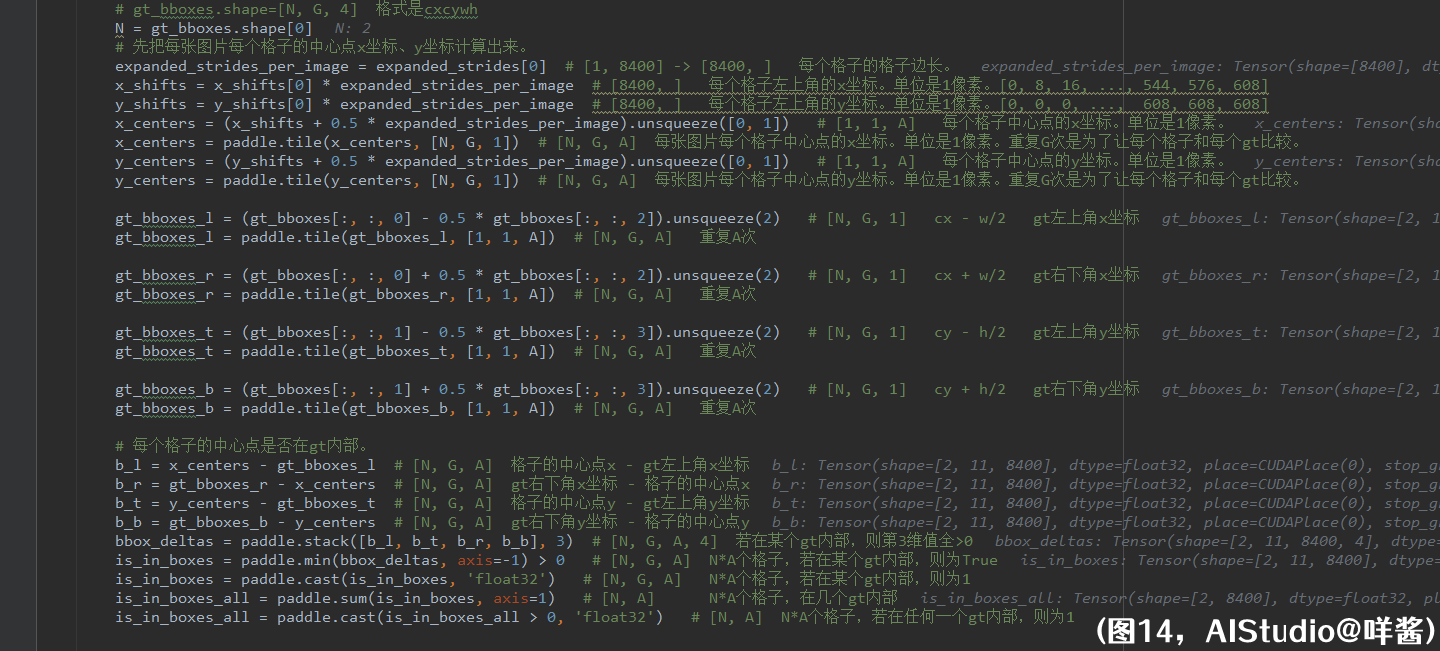
(图14)
get_in_boxes_info()里做的第一件事是计算每张图片所有格子和这张图片所有gt的两两之间的位置关系,即格子中心点是否在某个gt框内部。这句话有点长,没关系,我慢慢解释。我们有N张图片,每张图片有A个格子,每张图片有G个gt(包括了假gt)。所以我们需要用一个形状为(N, G, A)的张量表示这种位置关系。看代码,我们先把每张图片每个格子的中心点x坐标、y坐标计算出来。理论上来说,每张图片每个格子的中心点x坐标、y坐标可以分别用2个形状都为(N, A)的张量来表示。但是代码里却是用形状都为(N, G, A)的张量x_centers、y_centers来表示,这是为什么呢?因为我们需要计算的是每张图片所有格子和这张图片所有gt的两两之间的位置关系,所以每个格子的中心点x坐标、y坐标都重复了G次。接着,我们计算出gt左上角x坐标、gt右下角x坐标、gt左上角y坐标、gt右下角y坐标;这些坐标的形状都是(N, G, A),重复了A次,理由也是一样的,因为每个gt要和所在图片的每个格子计算位置关系,所以重复了A次。这时候,x_centers、y_centers、gt左上角x坐标、gt右下角x坐标、gt左上角y坐标、gt右下角y坐标形状都是一样的,都是(N, G, A),就可以开始计算了。怎么判断格子的中心点是否在gt内部呢?我们使用作差的方法,若格子的中心点在gt内部,那么b_l = 格子的中心点x - gt左上角x坐标、b_r = gt右下角x坐标 - 格子的中心点x、b_t = 格子的中心点y - gt左上角y坐标、b_b = gt右下角y坐标 - 格子的中心点y,这4个值肯定都大于0,等价于这4个值的最小值大于0,所以代码就用了paddle.min()实现。is_in_boxes这个张量表示格子中心点是否在某个gt内部。我举个例子给大家解释一下。

(图15)
比如这张图片有狗、自行车、汽车3个gt,即G3,gt框的颜色分别是黄、红、蓝。如果格子中心点位于对应的gt内,那么在格子里画上一个对应颜色的小圆点。那么一个格子里最多能画G3个小圆点。那么这张图(图15)其实就表示了代码里is_in_boxes这个张量,形状为(N, G, A)。G那一维表示一个格子里最多能画G个小圆点,N、A这两维表示了所有图片的所有格子。is_in_boxes里某个位置(r, s, t)的值为1,表示第r张图片第t个格子的中心点位于第s个gt的内部。这么说应该懂了吧?通过图15可以看出,is_in_boxes这个张量表示了格子中心点是否在某个gt内部。is_in_boxes_all形状为(N, A),表示N * A个格子,若在任何一个gt内部,则为1。
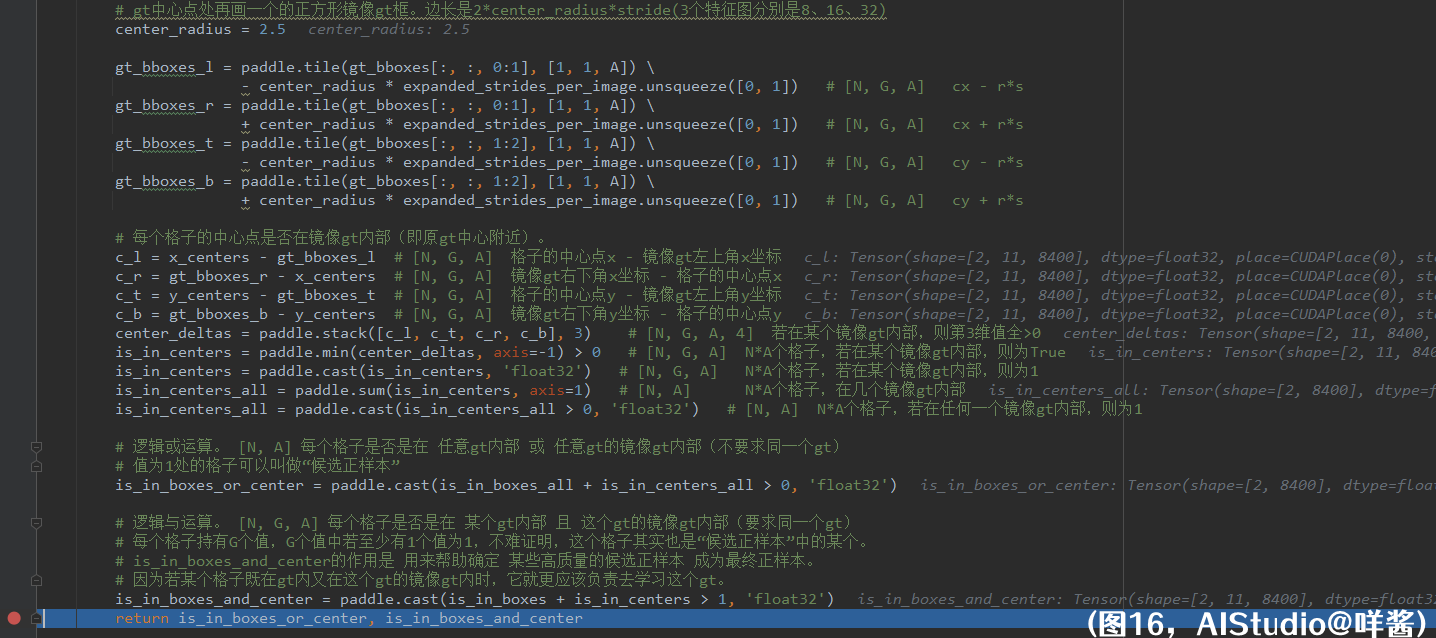
(图16)
接着往下看代码,作者为每个gt构造了一个对应的正方形镜像gt,镜像gt和原gt的中心点位置是一样的,但是边长变成了2 * center_radius * stride(3个特征图分别是8、16、32)。这里center_radius=2.5,也就是每个特征图下的镜像gt的边长为5倍格子边长。接下来的代码是计算格子中心点是否在某个镜像gt内部,同样使用作差的方法得到is_in_centers和is_in_centers_all。我同样画图出来给大家感受一下:

(图17)
镜像gt可能比原gt大,也可能比原gt小。如果格子中心点位于对应的镜像gt内,那么在格子里画上一个对应颜色的小圆点。经过同样的处理方式得到is_in_centers这个张量,形状为(N, G, A)。is_in_centers里某个位置(r, s, t)的值为1,表示第r张图片第t个格子的中心点位于第s个镜像gt的内部。镜像gt有什么用呢?其实就是用来判断格子中心点是否在原gt中心附近。另外,上文说到我用[-9999.0, -9999.0, 10.0, 10.0]这4个值初始化假gt,这是为了让假gt的镜像gt(它是有5个格子边长的。)不围住格子中心点,从而影响结果。试想一下,假如我用[0, 0, 0, 0]这4个值初始化假gt,那么假gt的镜像gt会包围住每张特征图左上角的格子,会影响后续计算。所以我把假gt设置在了第三象限,远离格子。(看回图16)is_in_centers_all形状为(N, A),表示N * A个格子,若在任何一个镜像gt内部,则为1。最后两句代码,is_in_boxes_or_center,形状为(N, A),表示每个格子是否是在 任意gt内部 或 任意gt的镜像gt内部(不要求同一个gt),值为1处的格子可以叫做“候选正样本”。is_in_boxes_and_center,形状为(N, G, A),表示每个格子是否是在 某个gt内部 且 这个gt的镜像gt内部(要求同一个gt)。每个格子持有G个值,G个值中若至少有1个值为1,不难证明,这个格子其实也是“候选正样本”中的某个。is_in_boxes_and_center的作用是 用来帮助确定 某些高质量的候选正样本 成为最终正样本。因为若某个格子既在gt内又在这个gt的镜像gt内时,它就更应该负责去学习这个gt。最后返回is_in_boxes_or_center、is_in_boxes_and_center。
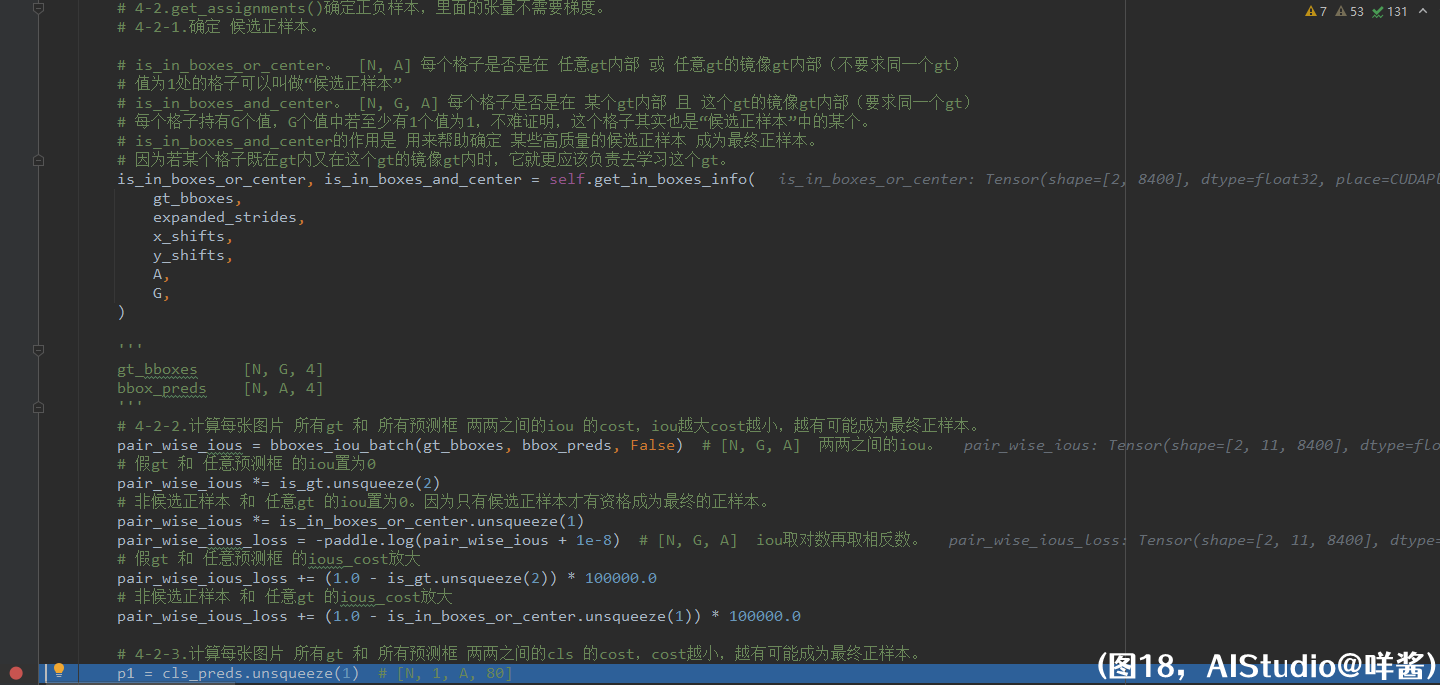
(图18)
历经千辛万苦,八戒、沙僧、唐僧师徒3人终于打败小boss,结界也被解除。悟空高兴地跳着奔向他们,重聚的欢笑难以消逝。殊不知,前面等待他们的竟是另一种别离。4-2-2步,计算每张图片 所有gt 和 所有预测框 两两之间的iou 的cost,iou越大cost越小,越有可能成为最终正样本。这里作者的变量名叫做loss,但其实是cost,cost和loss是有很大区别的,最大的区别是cost不用进行反向传播,它只是用来确定正负样本的。计算两两之间的iou是一项基本功,糖妹不会详细解释这里的代码,做法有点类似刚才计算格子和gt两两之间的位置关系,把gt_bboxes重复A次,把bbox_preds重复G次,使形状一样,再整体计算。返回一个形状为(N, G, A)的张量pair_wise_ious,表示两两之间的iou。然后,要将假gt 和 任意预测框 的iou置为0,因为不能用假gt确定最终正样本;将 非候选正样本 和 任意gt 的iou置为0,因为只有候选正样本才有资格成为最终的正样本。以不影响后续dynamic_k_matching()方法计算。接着,计算pair_wise_ious_loss,即格子和gt两两之间iou的cost,取对数再取相反数。可以看出来,若iou越大,iou的cost越小,越有可能成为最终正样本。而iou==0时,iou的cost为-ln(1e-8)=18.42068,iou的cost还是不够大,所以还要手动放大 假gt 和 任意预测框 的ious_cost,因为不能用假gt确定最终正样本。另外,还要放大 非候选正样本 和 任意gt 的ious_cost,因为非候选正样本没有资格成为最终正样本。pair_wise_ious_loss的形状是(N, G, A),用来帮助确定哪些格子是最终正样本,有G这个维是因为,不仅要确定某个格子是否是最终正样本,还要确定它和哪个gt有最小cost,以确定它负责学习哪个gt。
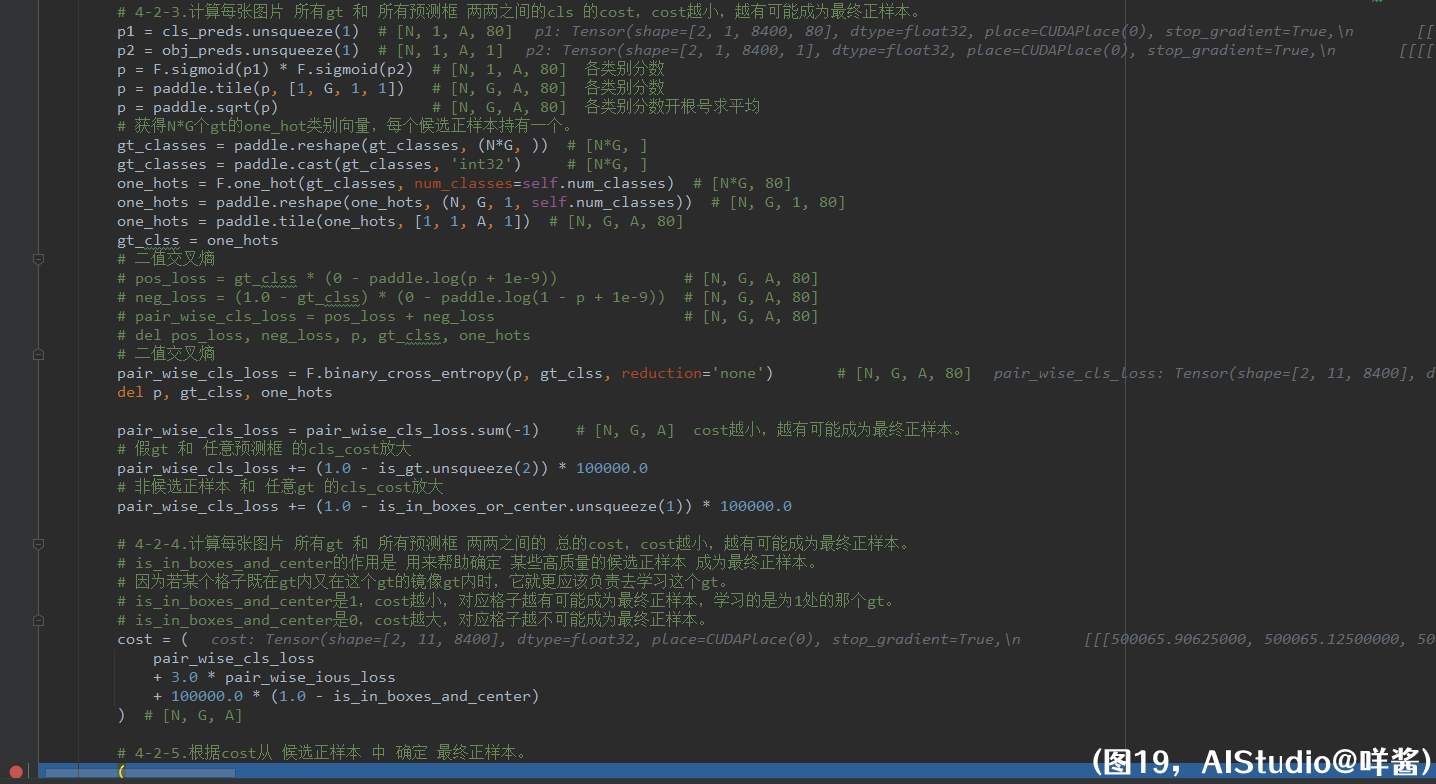
(图19)
4-2-3步,计算每张图片 所有gt 和 所有预测框 两两之间的cls 的cost,cost越小,越有可能成为最终正样本。首先,把各类别分数表示出来,即p=sigmoid(置信度) * sigmoid(各类别条件概率),再重复G次,因为是两两之间。再开根号求平均。然后,获取N * G个gt的onehot向量,onehot向量重复A次,因为是两两之间。再用二值交叉熵计算每张图片 所有gt 和 所有预测框 两两之间的cls 的cost,把表示类别的那维的cost加掉,形状同样变成了(N, G, A)。同样地,不能用假gt确定最终正样本,非候选正样本没有资格成为最终正样本。所以假gt 和 任意预测框 的cls_cost放大,非候选正样本 和 任意gt 的cls_cost放大。4-2-4步,计算每张图片 所有gt 和 所有预测框 两两之间的 总的cost,cost越小,越有可能成为最终正样本。总的cost是这样计算的,等于pair_wise_cls_loss加3倍的pair_wise_ious_loss加十万倍的(1.0 - is_in_boxes_and_center)。is_in_boxes_and_center的作用是 用来帮助确定 某些高质量的候选正样本 成为最终正样本。因为若某个格子既在gt内又在这个gt的镜像gt内时,它就更应该负责去学习这个gt。is_in_boxes_and_center是1,cost越小,对应格子越有可能成为最终正样本,学习的是为1处的那个gt。is_in_boxes_and_center是0,cost越大,对应格子越不可能成为最终正样本。总的cost的形状同样是(N, G, A)。
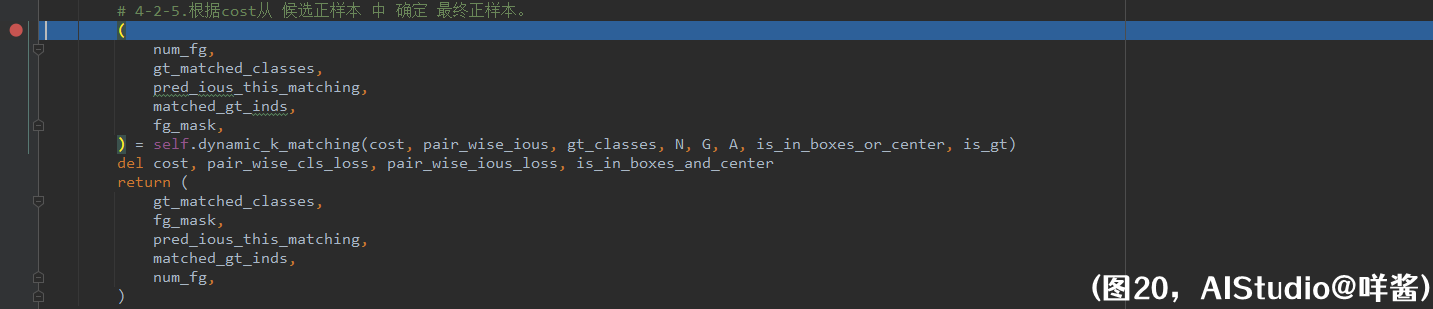
(图20)
4-2-5步,根据cost从 候选正样本 中 确定 最终正样本,并确定最终正样本学习的是哪个gt。dynamic_k_matching是关底的大boss,进去看看发生了啥。
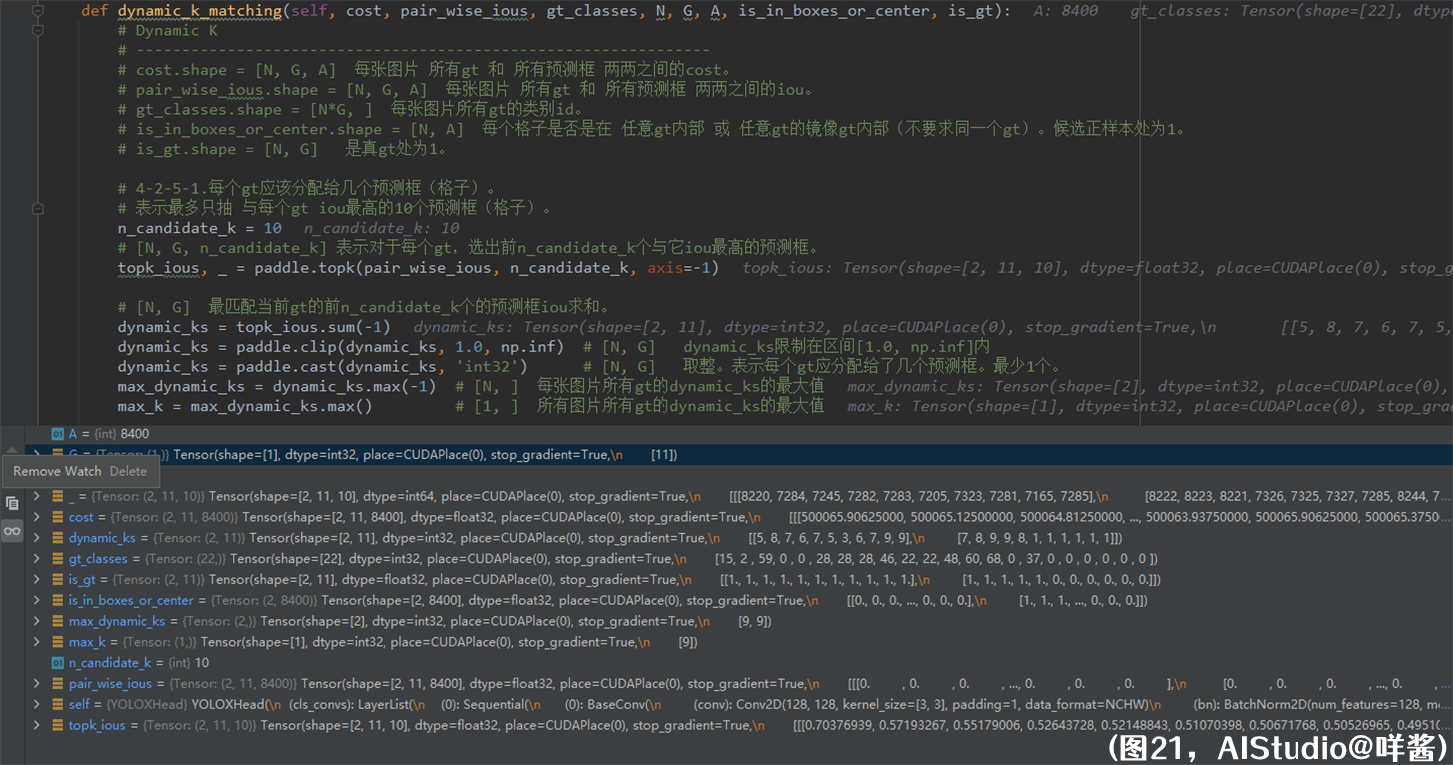
(图21)
传入的参数的形状和说明我在注释中打出来了,大家不用往前翻。4-2-5-1步,每个gt应该分配给几个预测框(格子)。对于每个gt,选出前10个与它iou最高的预测框。然后,把前10个的预测框iou求和,确定每个gt应分配给了几个预测框,得到dynamic_ks。而且dynamic_ks至少取1,将dynamic_ks转成整型。我们看dynamic_ks里面的数值,第0张图片11个真gt应该分别被分配给5、8、7、6、7、5、3、6、7、9、9个预测框,第1张图片的前5个真gt应该分别被分配给7、8、9、9、8个预测框,后6个假gt都应该分配给1个预测框。但是不能用假gt确定最终正样本。如何处理假gt呢?稍后会讲。最后求所有图片所有gt的dynamic_ks的最大值,得到max_k,这里是9。
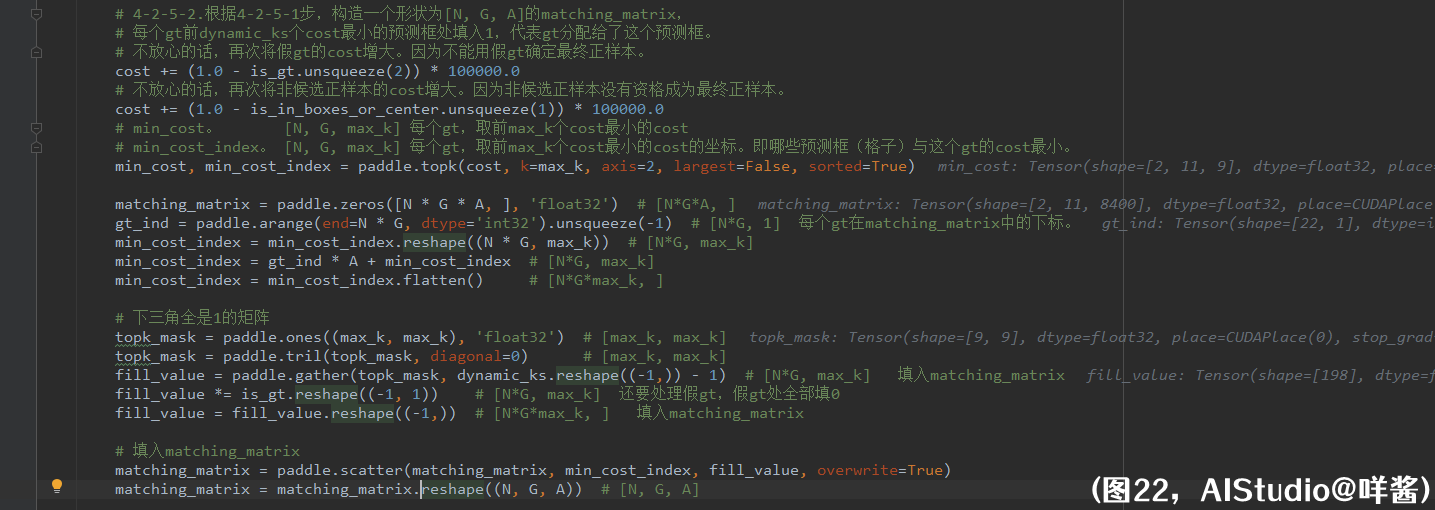
(图22)
4-2-5-2步,根据4-2-5-1步,构造一个形状为[N, G, A]的matching_matrix,每个gt前dynamic_ks个cost最小的预测框处填入1,代表gt分配给了这个预测框。不放心的话,再次将假gt的cost增大。因为不能用假gt确定最终正样本。不放心的话,再次将非候选正样本的cost增大。因为非候选正样本没有资格成为最终正样本。接着,我用paddle.topk()求cost在第2维的前max_k个最小值和最小值的坐标。我使用了sorted=True,因为并不是每个gt都被分配给了max_k个预测框,有的gt分配到的预测框个数小于max_k,所以需要排序,方便后面截断。min_cost的形状是[N, G, max_k],表示对于每个gt,取前max_k个cost最小的cost;min_cost_index的形状是[N, G, max_k],表示对于每个gt,取前max_k个cost最小的cost的坐标。即哪些预测框(格子)与这个gt的cost最小。注意,min_cost_index里的值的范围是0到A-1之间(包含0和A-1),即坐标是cost第2维的坐标。接着,构造一个形状为[N * G * A, ]的matching_matrix,这个矩阵是一个载体,为1处的地方表示这个gt分配给了第几个格子。刚才说到,min_cost_index里的值的范围是0到A-1之间,那么对应的预测框(格子)在matching_matrix中的坐标是怎么样的?我们还要加上每个gt的第0个格子在matching_matrix中的坐标,也就是gt_ind * A。整理min_cost_index,成为一个形状为[N * G * max_k, ]的张量,表示对于每个gt,取前max_k个cost最小的cost的坐标。坐标的范围是0到N * G * A - 1,即在matching_matrix中的坐标。对于某些gt,比如第0张图片的第0个gt,它在dynamic_ks中的值为5,小于max_k=9,也就是说,它只需要取与其cost最小的前5个预测框作为它的正样本,min_cost_index里多余的后4个预测框是不作为它的正样本的。咩酱他是怎么解决这个问题的呢?他太聪明了,他先构造一个下三角全是1的矩阵topk_mask,形状是(max_k, max_k),然后根据dynamic_ks里面的值抽出对应一行得到fill_value,形状是(N * G, max_k)。比如说第0张图片的第0个gt,它在dynamic_ks中的值为5,它的fill_value应该是[1, 1, 1, 1, 1, 0, 0, 0, 0],即前5个值为1,后面4个是0。另外,第1张图片有6个假gt,它们在dynamic_ks中的值为1,它们的fill_value是[1, 0, 0, 0, 0, 0, 0, 0, 0],这里我把它们的fill_value全部置0,通过乘以is_gt实现,这样的话假gt填入matching_matrix中的值全部是0了,假gt不分配正样本。然后,把fill_value reshape成和min_cost_index一样的形状[N * G * max_k, ]。最后,使用paddle.scatter()这个api把matching_matrix在min_cost_index处的元素修改为fill_value里面的值,reshape成[N, G, A]的形状,为1处的地方表示这个gt分配给了这个预测框。
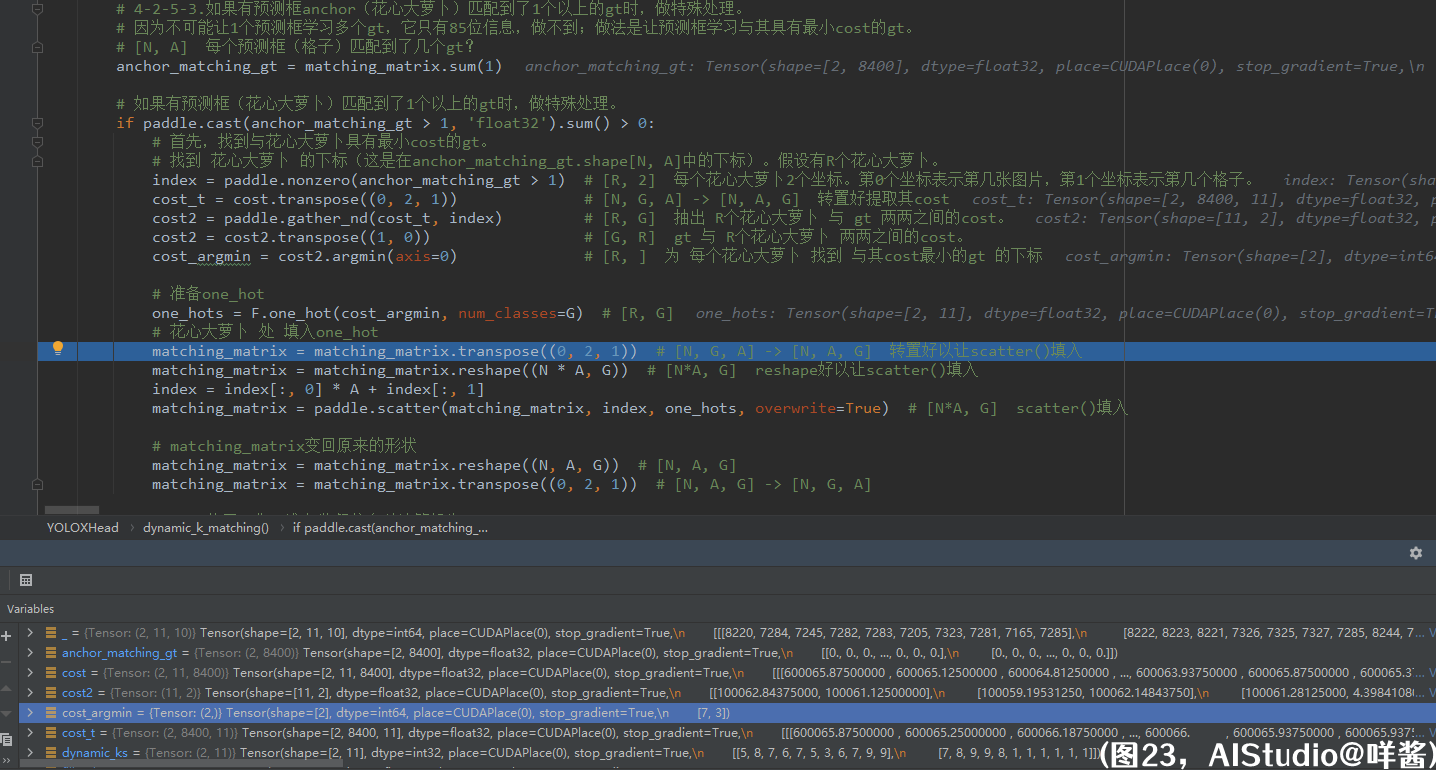
(图23)
4-2-5-3步,如果有预测框anchor(花心大萝卜)匹配到了1个以上的gt时,做特殊处理。因为不可能让1个预测框学习多个gt,它只有85位信息,做不到;做法是让预测框学习与其具有最小cost的gt。对matching_matrix的第1维求和,得到anchor_matching_gt,形状是[N, A],表示每个预测框(格子)匹配到了几个gt。如果有预测框匹配到了1个以上的gt时,做特殊处理。怎么处理呢?首先,找到与花心大萝卜具有最小cost的gt。找到 花心大萝卜 的下标(这是在anchor_matching_gt.shape[N, A]中的下标)。假设有R个花心大萝卜。那么index的形状是[R, 2],这里R==2,而且发现这2个花心大萝卜都是第0张图片的预测框,因为它们的第0个坐标都是0。接着把cost转置一下,形状变成[N, A, G],方便抽出 R个花心大萝卜 与 gt 两两之间的cost。最后,为 每个花心大萝卜 找到 与其cost最小的gt 的下标cost_argmin,形状为[R, ]。接下来要做的事是把matching_matrix中花心大萝卜处的长度为G的向量修改为只有在最小cost的gt处为1的onehot向量。所以,先准备onehot向量,在最小cost的gt处为1。one_hots是一个形状为[R, G]的张量。把matching_matrix的形状变换成[N * A, G]方便填入。index是花心大萝卜在anchor_matching_gt.shape=[N, A]中的坐标,为了变换成在matching_matrix.shape=[N * A, G]中第0维的坐标,需要把index的第0维坐标乘以A加上index的第1维坐标。同样地,使用paddle.scatter()这个api把matching_matrix在index处的元素修改为one_hots里面的值,填入的是onehot向量,即此时花心大萝卜变成了只学习与其具有最小cost的那个gt。最后,matching_matrix变回原来的形状[N, G, A]。
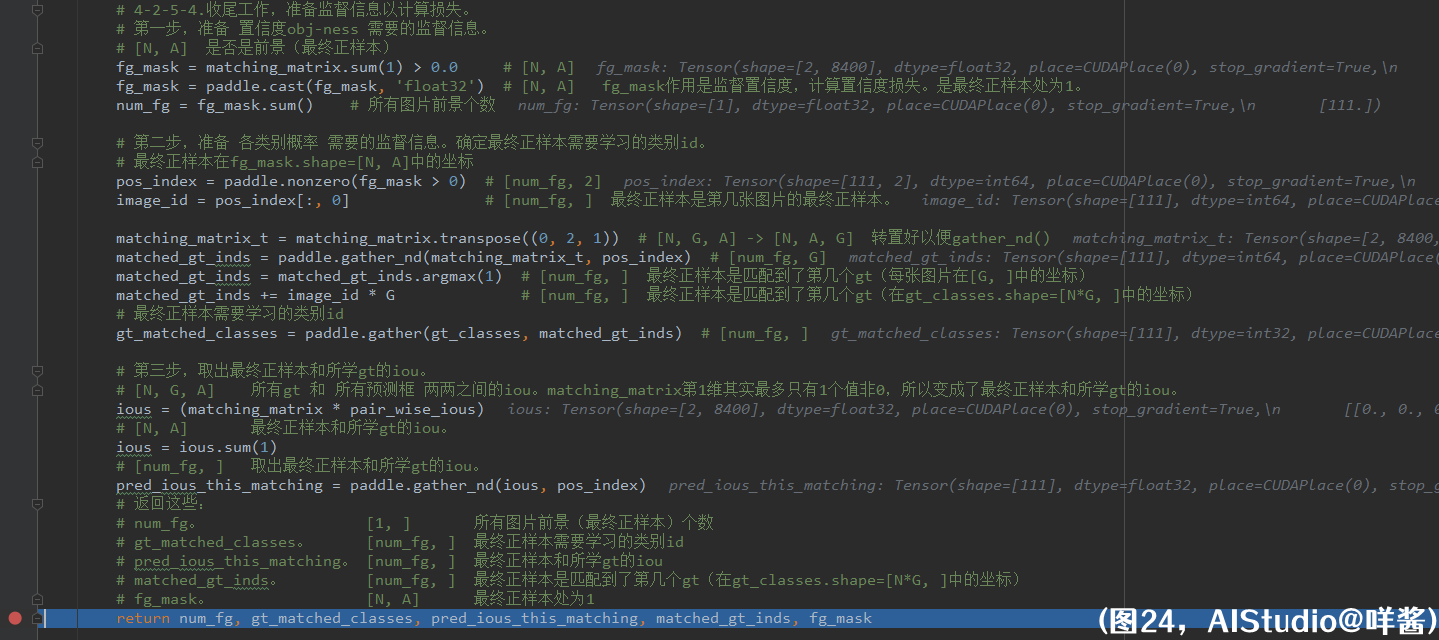
(图24)
4-2-5-4步,做一些收尾工作,准备监督信息以计算损失。第一步,准备 置信度obj-ness 需要的监督信息。matching_matrix第1维求和得到fg_mask,fg_mask作用是监督置信度,计算置信度损失。是最终正样本处为1。fg_mask求和得到所有图片前景个数num_fg。第二步,准备 各类别概率 需要的监督信息。确定最终正样本需要学习的类别id。先计算最终正样本在fg_mask.shape=[N, A]中的坐标pos_index,形状为[num_fg, 2]。只取pos_index的第0个坐标得到image_id,表示最终正样本是第几张图片的最终正样本。然后抽出matching_matrix中属于最终正样本的长度为G的向量,也是onehot向量。用argmax()算出第几个gt处为1。考虑到这是第几张图片的最终正样本,matched_gt_inds还要加上image_id * G才能得到最终所需要学习的gt的坐标(在gt_classes.shape=[N * G, ]中的坐标)。最后,把最终正样本需要学习的类别id抽出来。第三步,取出最终正样本和所学gt的iou。先计算ious = (matching_matrix * pair_wise_ious),matching_matrix第1维其实最多只有1个值非0,所以变成了最终正样本和所学gt的iou。ious把第1维加掉,还是最终正样本和所学gt的iou。最后,用gather_nd()取出最终正样本和所学gt的iou,它的形状是[num_fg, ]。然后返回这些张量。

(图20)
程序从dynamic_k_matching()方法返回后删除了一些中间变量,释放内存,也马上从get_assignments()方法返回,SimOTA部分结束。咩酱将SimOTA并行化,全程不使用for循环。
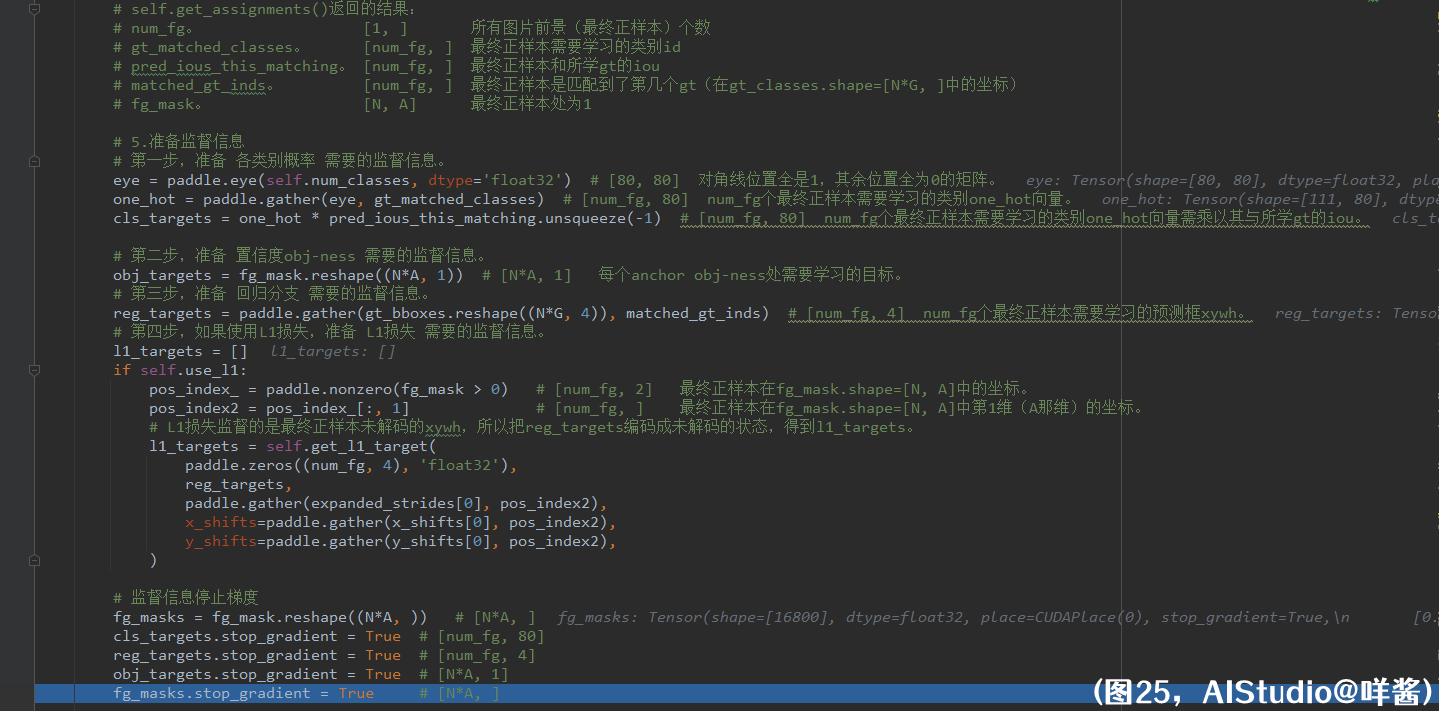
(图25)
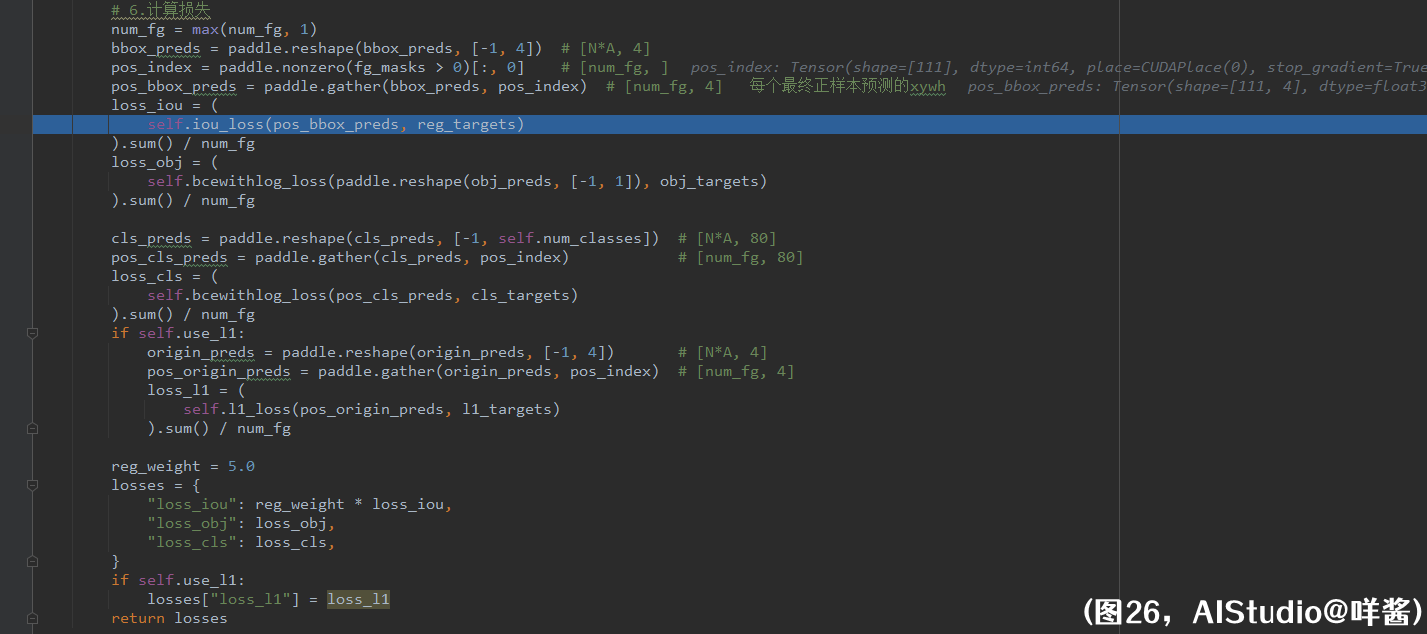
和SimOTA一样,实现损失时,咩酱逐个对比了pytorch原版与paddle版的每个中间变量,结果是一样的,请大家放心使用loss部分。我把self.get_assignments()返回的结果打在了注释里,让大家不用往回翻。get_losses()方法的第5步,准备监督信息。第一步,准备 各类别概率 需要的监督信息。首先准备一个对角线位置全是1,其余位置全为0的矩阵。形状是[80, 80],根据gt_matched_classes提供的最终正样本需要学习的类别id抽出每个最终正样本需要学习的类别one_hot向量。num_fg个最终正样本需要学习的类别one_hot向量需乘以其与所学gt的iou。为什么要这么做?我也不懂,我只是个搬砖的。第二步,准备 置信度obj-ness 需要的监督信息。只要把fg_mask给reshape一下就好了。第三步,准备 回归分支 需要的监督信息。把每个最终正样本需要学习的gt的xywh抽出来即可。第四步,如果使用L1损失,准备 L1损失 需要的监督信息。L1损失监督的是最终正样本未解码的xywh,所以把reg_targets编码成未解码的状态,得到l1_targets。最后,监督信息停止梯度。
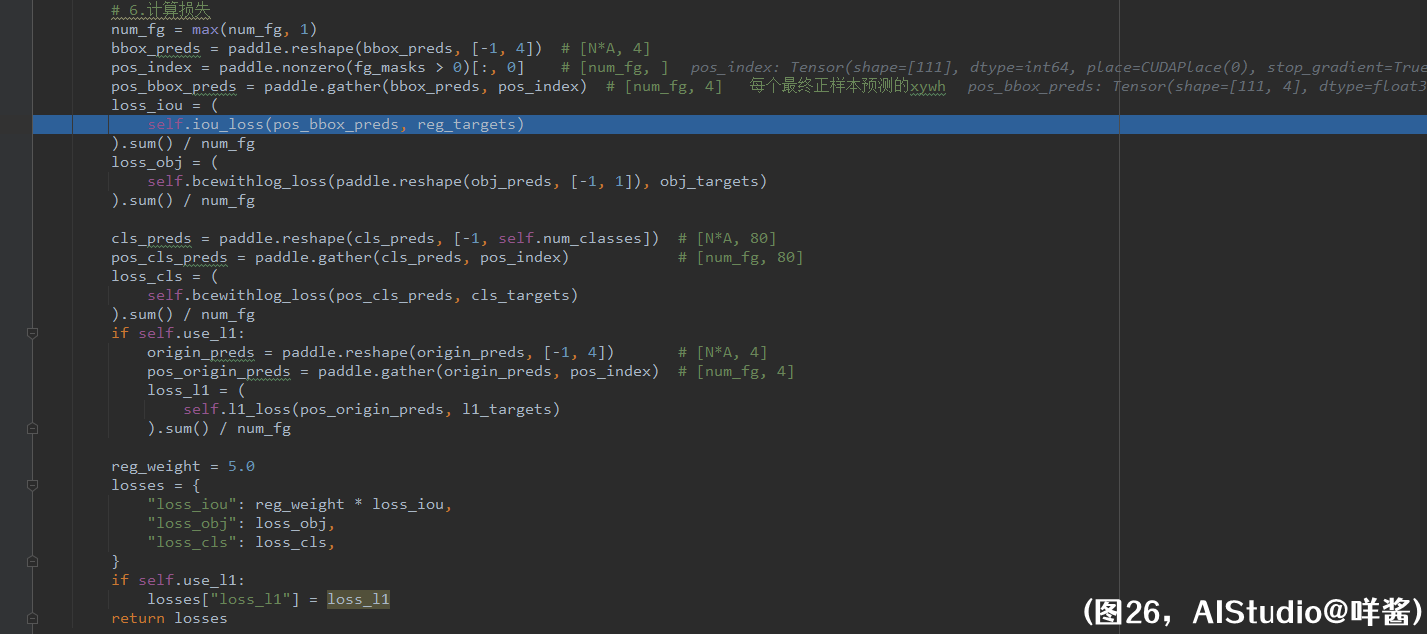
(图26)
get_losses()方法的第6步,计算损失。首先,把每个最终正样本预测的xywh抽出来,再和reg_targets计算损失,使用的是iou损失,仅最终正样本(num_fg个)计算iou损失。我们看看iou损失的计算:
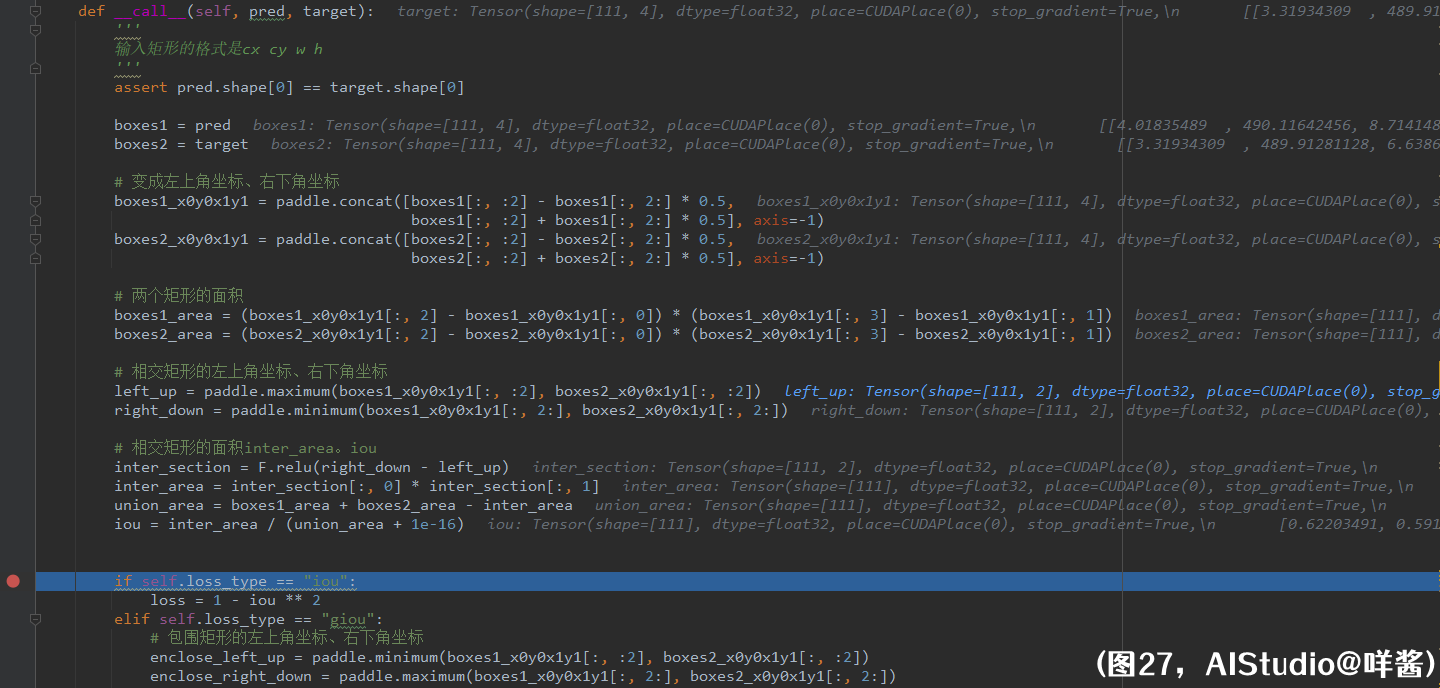
(图27)
需要先把预测框和其所学gt的iou求出来。pred和target的形状都是[num_fg, 4],里面的值都是表示框的中心点xy坐标+框的宽高。首先,boxes1和boxes2都变成左上角坐标、右下角坐标格式。然后分别求出每个预测框和每个gt的面积。接着,求预测框和所学gt的相交矩形的左上角坐标、右下角坐标。
(图28)
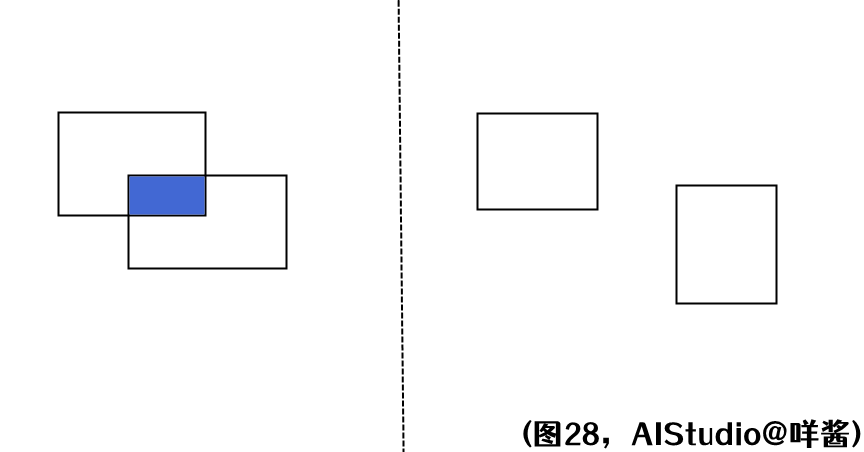
如图28的左图所示,两个矩形的相交矩形为蓝色矩形,蓝色矩形左上角坐标应等于预测框左上角坐标和gt框左上角坐标逐元素取最大,蓝色矩形右下角坐标应等于预测框右下角坐标和gt框右下角坐标逐元素取最小,所以代码中使用了paddle.maximum()和paddle.minimum()实现。另外,可能两个矩形没有重叠区域,如图28的右图所示。假如此时按照刚才的算法求相交矩形的左上角坐标、右下角坐标,那么得到的相交矩形的左上角坐标x0y0应该是右下矩形的x0y0,得到的相交矩形的右下角坐标x1y1应该是左上矩形的x1y1,易知相交矩形的x0 > x1、y0 < y1,导致计算相交矩形的面积时宽是负数,(切回图27)所以我对相交矩形的宽、高用了一个relu()激活函数,即当不存在相交矩形时,相交矩形的面积为0。最后就是套用iou的计算公式了,iou=交集面积/并集面积。最后iou_loss = 1 - iou ** 2,iou的值为0到1之间,iou越大,表示预测框和所学gt越接近,此时loss越小。另外,假如你使用的是giou损失,还要额外计算giou,giou很好计算,用一个最小的矩形把预测框和gt包围起来,如图29所示:

(图29)
红框矩形就是所求的包围矩形。如何求这个包围矩形的左上角坐标、右下角坐标呢?包围矩形左上角坐标应等于预测框左上角坐标和gt框左上角坐标逐元素取最小,包围矩形右下角坐标应等于预测框右下角坐标和gt框右下角坐标逐元素取最大。和求相交矩形的算法就差一点,逐元素取最大、最小切换一下就行了。代码就这样写:

(图30)
然后求包围矩形的面积,包围矩形的宽高肯定都是正数,所以不用relu()。然后giou = iou - (enclose_area - union_area) / enclose_area = iou - 黄色区域面积 / 包围矩形的面积,如图29所示。 黄色区域面积 / 包围矩形的面积 的取值范围是0到1之间,当这个比值接近1时,表示预测框和gt离得很远,当这个比值接近0时,表示预测框和gt非常接近。所以这个比值越小越好,而giou = iou - 这个比值,可以看出,iou越大,这个比值越小,那么giou越大,表示预测框和gt越接近。giou的取值范围是-1到1之间(想象一下,当两个矩形重合时,giou1;当两个矩形无穷远时,giou-1)。giou_loss = 1 - giou的取值范围是0到2之间。giou越大,表示预测框和gt越接近,giou_loss也越小。
(图26)
计算完iou损失后,计算置信度损失,使用的是二值交叉熵损失,所有样本(N * A个)都计算置信度损失。接着,计算cls损失,把所有最终正样本预测的类别向量抽出来,再和cls_targets计算损失,使用的是二值交叉熵损失,仅最终正样本(num_fg个)计算cls损失。最后,如果使用L1损失,把所有最终正样本预测的未解码的xywh抽出来,再和l1_targets计算损失,使用的是L1损失,即绝对值损失,仅最终正样本(num_fg个)计算L1损失。把这些损失整理成字典返回,其中iou损失的权重是5。至此,loss部分讲解结束(完结撒花)!
感谢YOLOX的作者团队!感谢百度飞桨AIStudio提供给我这样的展示自己的机会!特别感谢PaddleDetection,可以说PaddleDetection是我的老师,飞桨2.x的写法、数据预处理方法、损失函数的写法等等,都是我从PaddleDetection中学习到的,学习PaddleDetection真的让我提升很多。另外,实现YOLOX中并行版SimOTA时,也遇到很多困难,比如怎么一批图片同时处理、怎么修改张量中某些位置的元素等等,一开始我想到SimOTA和SSD中的在线难样本挖掘有点类似,所以翻阅了PaddleDetection中SSDLoss里的代码,获得了很多灵感才把并行版SimOTA实现出来,再次感谢PaddleDetection!最后感谢咩酱的刻苦钻研!
宅男,喜欢拍视频,因为没有流量只能被迫女装出道,是一个被深度学习耽误的歌手、摄影师、导演、演员。(开玩笑的,不要信!)
哈哈!还没有跟大家正式介绍过我自己。我是咩酱,之前本科毕业于南京大学(以一个学渣的身份,并不值得大家效仿)。如果有人问我有想对在校大学生说些什么吗?我会说,不要虚度年华,人生需要一直学习!毕业后的第一份工作做的是java工程师,由于工作内容太过枯燥(天天写网页and爬虫),这些都不是我想要。偶有一天以前的我对我说,咩酱,你别做java了,最适合你的是数学。于是乎一言不合就裸辞自学AI(95后就是这么任性呢)。我并没有这方面的基础就入坑AI的,读者如果是学生的话,希望你们要珍惜在校的学习机会!因为一些机缘巧合认识飞桨,并走到今天这一步,非常感谢飞桨给我这一个表现自己的机会。
(糖妹抢过话筒)
其实,我最有权发言了,和你朝夕相处那么久,我还不了解你吗?咩酱他是一个低耦合的人,对别人的依赖几乎没有,他一个人抗下了生活的一切。咩酱这些年学会的一件事是怎么和自己相处,怎么认识真正的自己。但是他一点都不感觉到孤单,一方面是有糖妹的全程陪伴,另一方面是在AIStudio这个平台遇到志同道合的你们。欢迎大家来B站找我玩耍!点个关注不迷路!
我的兴趣爱好广泛,喜欢女装、唱歌,最喜欢的歌手是周杰伦。
可不可以给女装大佬点个关注and三连!嘤嘤嘤~
B站: _糖蜜
AIStudio: asasasaaawws
GitHub: miemie2013

联系我们
电话:400-123-4567
手机:138 0000 0000

公司地址
地址:广东省广州市天河区88号

公司名称
顺盈平台官方指定注册站






 QQ在线咨询
QQ在线咨询  400-123-4567
400-123-4567