

误差梯度是神经网络训练过程中计算的方向和数量,用于以正确的方向和合适的量更新网络权重。 在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。 网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。 梯度爆炸引发的问题 在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
某些情况下梯度趋近于0导致无法更新。
在某些情况下,梯度会变得非常小,有效地阻止了权重值的变化。在最坏的情况下,这可能会完全停止神经网络的进一步训练。例如,传统的激活函数(如双曲正切函数)具有范围(0,1)内的梯度,反向传播通过链式法则计算梯度。这样做的效果是,用这些小数字的n乘以n来计算n层网络中“前端”层的梯度,这意味着梯度(误差信号)随n呈指数递减,而前端层的训练非常缓慢。
传统的SGD算法
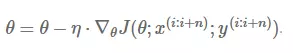
Momentum算法
参考链接:https://distill.pub/2017/momentum/
原文链接:On the importance of initialization and momentum in deep learning
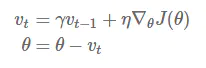
从公式可以看出相对于SGD算法,Momentum算法吸取了之前梯度下降的信息
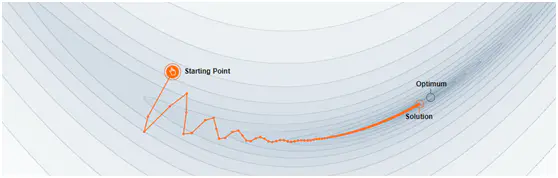

像传统的SGD就会卡在第三个小球那块,而Momentum算法,由于小球在之前的下降过程中,积攒了一些能量,有可能在学习中越过这个局部最优点。
paddlepaddleAPI代码:

对于学习率,一般训练越久步长应该越小,adagrad算法除以一个时间的根号,可以使学习率随着时间减少。
gt是当前梯度。
ot是之前梯度的累加,如果之前存在大梯度值,可以使这次更新步长减少。
百度API描述链接
最后附上课程链接:https://aistudio.baidu.com/aistudio/course/introduce/1978

联系我们
电话:400-123-4567
手机:138 0000 0000

公司地址
地址:广东省广州市天河区88号

公司名称
顺盈平台官方指定注册站






 QQ在线咨询
QQ在线咨询  400-123-4567
400-123-4567